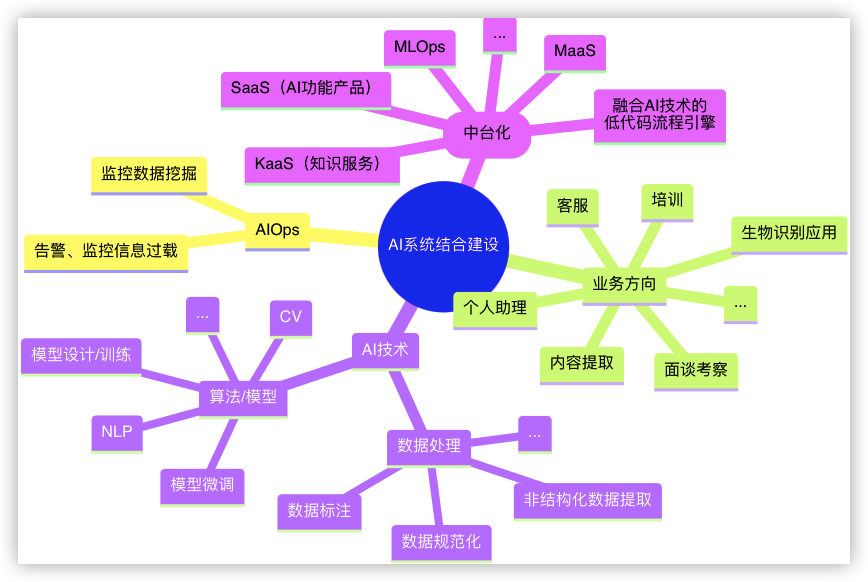
数据中台与技术漫谈
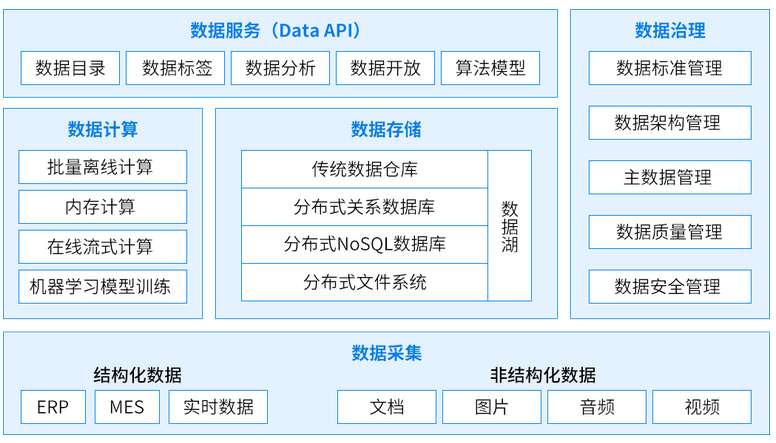
数据中台与技术漫谈
DiffDay
数据中台
数据中台并不产生数据,而是将组织在业务中产生的全域数据,汇进数据中台建立一套标准,形成数据资产后再进行服务化,业务化的过程。
目标
目标在于提升运营效率,决策效率,数据精准。对外支撑各种场景应用。
- 在实施上把数据加工,存储,分析,建模等与数据相关的所有事情都可轻松的解决
- 从管理上把一切的数据,口径,项目,工程等都管理起来
- 面对客户,使客户一站式在此平台上获取到任何想要的数据,有足够的数据应用能力
价值锚定
梳理业务场景:搞清楚中台如何对业务产生价值,回归到业务本质,如何提升商业能力
工作范畴
工作内容涵盖:(1) 数据标准和指标建设 (2)数据采集(3)数据集成(4)数据治理(5)数据应用(6)数据资产管理(7)大数据仓库等技术应用
能力建设
复用性,资源整合,能力沉淀,数据深度整合沉淀为公共数据服务,这些能力在构建数据中台之初就是必须去直面的问题。
-
能力沉淀:(1)数据接入能力(2)计算能力(3)存储能力(4)业务支撑能力(5)展现能力
-
数据域的建设,分为
- 内容建设
- 工具建设:(1)ETL 过程(2)数据工具(3)调度工具(4)元数据工具(5)指标字典(6)库表字典(7)数据质量
内容价值探索,工具体系化建设是数据平台的基石,内容透过工具提取出价值
指标字典:解决公司指标管理,口径管理的问题
每个工具产品解决特定领域的问题
数据治理怎么强调都不为过
和业务独立开的数据治理少有成功的,治理需要跟业务场景紧密结合
-
大的数据标准要有(数据资产目录),通过数据资产目录将共有的维度,共性的业务模型提炼出来
-
建立统一的企业级数据指标体系,解决数据来源多元化和标准不统一的问题。规范有序的完成数据采集,建模,分析,集成,应用和资产管理
block
columns 6
a["应用"]:1 block:application:5
服务使用分析 服务提升建议 趋势分析 个性服务推荐 影响分析
end
v["可视化"]:1 block:visualization:5
报表 大屏
end
s["服务管理"]:1 block:service:5
服务创建 API 管理
end
m["资产管理"]:1 block:management:5
资产门户 标签管理 价值评估 标准管理
end
p["资产建设"]:1 block:property:5
数据交换
dd["数据开发"]
算法建模
end
block:develop:6
可视化开发IDE 任务发布管理 任务调度管理 任务运维监控
end
i["基础设施层"]:1 block:infrastructure:5
AWS S3["Amazon S3云存储"] RDS ...
end
dd-->develop
data["各类数据源"]:6
算法建模管理
block columns 7 a["分类"] block:a1:6 逻辑回归算法 SVM算法 ID3算法 C4.5算法 随机森林算法 end b["回归"] block:b1:6 线性回归模型 朴素贝叶斯模型 Lasso回归模型 Ridge回归模型 end c["聚类"] block:c1:6 K均值算法 高斯混合模型 DBSCAN算法 幂迭代聚类模型 隐含狄利克雷分布 end d["关联降维"] block:d1:6 Apriori d2["FP-growth"] SVD奇异值分析 PCA主成分分析 end e["时间序列"] block:e1:6 AR模型 MA模型 ARIMA模型 ARCH模型 GARCH模型 end f["识别"] block:f1:6 产业舆情矩阵模型 产品价格弹性模型 产业聚集度模型 团伙分析模型 重点人员行为模型 商标相似度检测模型 end g["预测"] block:g1:6 企业成长性模型 重要商品价格预测模型 钢铁企业融资模型 环境预警模型 销售订单预测模型 end h["优化"] block:h1:6 资本热度模型 景气指数模型 克强指数模型 fp[" 扶贫资金分配优化模型 "] other["..."] end
团队划分
- 业务专家团队+数据治理团队
- 数据工程团队(平台)+数据分析团队
- 智能算法团队
数据中台和数据平台有一个潜台词的区别,就是最终会有数据服务化的目标,提高数据共享能力,治理的好避免数据的重复计算
一般一上来就喊中台化的基本入不敷出,不是人员投入问题,就是实施方向以及定位到底是什么不明确,有的企业用演进的办法来做实施是个非常不错的选择。
失败的数据中台常碰到如下问题
- 「人的争斗」:有几方人/势力都想驱动这个平台,想法太多
- 「能力问题」:做中台难度和普通产品比,有量级的差异,能力不足,真搬不动这块石头还砸自己的脚
- 「头疼医头」:原本一条线到头的建设,实际上变成头痛医头的复杂网建设
- 「高投低产」:资源问题,产研几十位,运营几十,数据人员几十,审核人员可能上百,算上流动,前后大概可能有好几百人。如果一开始给了老板很高的预期,希望花一年的时间几十人就能完成中台的建设,到头来不断降低预期,投入产出比不断透支,可想最终的结果
数字化转型,忐忑艰苦
---
title: 数据体系建设
---
flowchart LR
A[自身建设方向] --> B(数据分析)
A --> C(数据产品化)
A --> D(数据内容建设)
A --> E(数据建设前置与标准化)
D --> F[交易方向]
D --> G[流量方向]
指导思想
被动响应转主动建设,修炼内功,降本增效
- 工具建设提升自身效率(标准化,组件化,内部运营工具)
- 沉淀优化内容建设
- 围绕业务场景化做敏捷探索
总结与例说
综合言之:支持业务商业模式不停快速尝试下的数据场景化需求,还要进行自身内容与工具化建设,拆解历史包袱 !
flowchart LR
系统化 --> 业务在线化 --> 业业务智能化务信息化 --> 数据整合化 --> 业务智能化
也有企业信息化能一部到位,毕竟这样的很少,更多是原来资源的整合升级。
举例:
-
定制化的数据产品改成了可配置化,持续做减法,表从近万张缩减到几千张,成千的指标一样做缩减
-
通过该数据做数据作战地图–数据产品的方式来做数据模型的阶段性布局和设计(定优先策略)
过去的债务
在过去企业构建IT基础设施的过程中,逐渐形成了各种烟囱式的数据设施,也带来了数据孤岛问题,还有一点可怕的事是:ETL任务和中间过程大量膨胀,不仅是存储问题,更大的挑战是无数的ETL任务其实不断地做重复性的工作,不断消耗整个数据集群的资源,还存在数据口径不一致的问题。数据来源又可能有分歧,如这个部门说自己是从PowerBI中看到的,另一个部门说是从数仓里看到的,这就不能帮助企业做出高效的决策。
过去上了ERP到电子化时,就有一个企业流程再造的说法,就是说你上系统要先梳理自己的业务流程,梳理不好系统上不去,也没法提升管理能力。现在和那个阶段有一点味道相像,一样要先将企业的指标,数字化运营的思路理清楚,如果讲不清业务目标,过程目标,结果目标,那就不知道拿什么追踪,拿什么来做数字化的管理?
各部门各组织都非常有欲望生产自己的数据指标,会形成几百倍的放大。不同部门指标不统一,指标过时,都属于管理问题。
古早技术概念介绍
数仓的星型和雪花模型(多表组合模型)
区别就是对维度表的拆分,雪花模型维度表设计更加规范,一般符合第三范式;而星型一般采用降维操作,用冗余避免模型过于复杂,提高易用性和分析效率。
在数据仓库中多用星型模型,构建宽表,维度整合,减少多表关联,方便性能高。
在数据采集中,要注意完整性校验,针对缺失字段的数据建议直接丢掉,也可以用同列前/后一个数据来填补。还要注意合法性校验,异常值全部替换为一个特殊值(特殊值这要根据具体的业务场景而定)
宽表模型和多表组合模型
| 宽表型 | 组合模型 |
|---|---|
| Elasticsearch、Solr 应用Scatter-Gather计算模型 |
GreenPlum |
| ClickHouse | Presto |
| Druid | Impala |
宽表模型能提供比多表模型更好的查询性能,不足的是支持的 SQL 操作类型比较有限,如对 Join 等复杂操作支持较弱或不支持。
多表组合模型一般均基于 MPP 架构,相较其它类型的 ROLAP 和 MOLAP,通常不具有性能优势,实时性较一般。但其支持的数据量大,支持 SQL 类型多样,这样通用系统往往比专用系统更难实现和进行优化。
基于明细数据的多维模型、雪花模型能支持业务灵活用数问题,但性能问题令人头疼,ROLAP 开发简单但效率完全依靠数据库本身,当数据量到一定程度后很难保证性能,所以又出现了大量为解决性能而开发的报表物理表(宽表),MOLAP 能解决效率方面很多问题,但相对于 ROLAP 会带来管理运维成本的增加。
基数估计
Cardinality Estimation一直是大数据领域的重要问题之一:一批数据中,不重复的元素有多少个。以 UV 为例,对访问量巨大的系统来说,统计出 10 亿和 10 亿零 10w 其实没太多的区别,因此,在这种业务场景下,为了节省成本,可只计算出一个大概的值,没必要算出精准的值。
大家常规用字典的数据结构,遍历字典后,得到的整体计数就是这批数据的基数了。这种算法虽然精准度很高,但使用的空间复杂度却很高,故提出一些近似方法,估算数据集合的基数。如 HyperLogLog,MinCount,ThetaSketch
OLTP vs OLAP
-
与 OLAP 不同,OLTP 系统强调数据库内存效率,强调内存各种指标的命中率,强调并发操作,强调事务性
-
OLAP 系统则强调数据分析,强调磁盘 I/O,强调分区。它是一种让用户可以用不同视角方便快捷分析数据的计算方法,主流 OLAP 可分为三类
-
MOLAP:多维 OLAP,Multi-dimensional:典型代表是:Druid,Kylin,Doris,它们一般会根据用户定义的数据维度,度量(也可以叫做指标)在数据写入时生成预聚合数据;Query 查的是预聚合数据而不是原始明细数据,不支持明确数据的查询,仅适合这种查询场景相对固定且对查询性能要求非常高的场景。其优缺点都来自于其数据预处理环节,预聚合处理需预先定义维度,会限制后期数据查询的灵活性,如果查询工作涉及新的指标,需重新增加预处理流程。
-
ROLAP:关系型 OLAP,Relational。典型代表是:Presto,Impala,GreenPlum,Clickhouse,ES,Hive,SparkSQL,FlinkSQL。数据写入时,ROLAP 并未应用像 MOLAP 那样的预聚合技术,ROLAP 收到 Query 请求时,会生成执行计划,扫描数据,执行关系型算子,在原始数据上做过滤,聚合,关联,分组,排序,整个过程都是即时计算,拼的都是资源和算力的大小。ROLAP 不需要进行预处理,因此查询灵活,可扩展性好,这类引擎使用 MPP 架构(与 Hadoop 相似的大型并行处理架构,可通过扩大并发来增加计算资源),可高效处理大量数据。有人说 Spark SQL 和 Flink SQL 属于 DAG 模型,其实 DAG 并不算一种单独的模型,它只是生成执行计划的一种方式。
Hive执行 ad-hoc 查询慢的痛点,推动了 MPP 内存迭代和 DAG 计算模型的发展。
MPP减少 IO资源消耗,充分利用 CPU 资源,但事情往往是两面的。中间结果不落盘,正常情况是利好,异常情况如出现节点宕机,需要重新计算中间结果,拖慢任务完成时间。另扩展性没有 MR 架构好,随着 MPP 系统节点增多到一定规模,源于木桶效应,性能无法线性提升,且规模越大,出现宕机、坏盘等异常情况就会愈频繁,会导致 SQL 重试概率提升。所以 MPP比较适合执行时间不会太久的业务场景,如数小时,因为时间月越久,故障概率越大。
-
HOLAP:混合 OLAP,Hybrid。将聚合信息存储在 OLAP 服务器上,详细记录保留在关系表中,因此不会保留重复副本,平衡了磁盘空间需求。劣势正是同时支持 MOLAP 和 ROLAP,本身体系结构非常复杂。
或者换种说法其允许模型升级者决定哪些数据存储在 MOLAP 中,哪些数据存储在 ROLAP 中,把数据划分成传统关系型存储(细节数据)和专有存储(聚合数据)
-
OLAP 脑图
mindmap root((OLAP)) ROLAP)ROLAP( MPPDB Doris/StarRocks ClickHouse GreenPlum SQL-On-HadoopNaN MPP架构))MPP架构(( Presto Impala Drill HAWQ 通用型))通用型(( Hive SparkSQL MOLAP Kylin Druid HOLAP Microsoft SQL Server Analysis Services
并发差异
在 OLAP 场景,一般认为 QPS 达到1000+就算高并发,而不是 10w 以上才算,毕竟数据分析场景,数据海量,计算复杂,达到 1000 已经非常不易。
如 Clickhouse 在 TB 级别,单集群达到 100 已经很困难,更适合企业内部 BI 报表使用,而不是广告主平台报表。Clickhouse 的执行模型决定了它会尽全力来执行一个 query,而不是同时执行很多 query
Hadoop的调度演进
在 Hadoop1 中,MapReduce计算框架既负责集群资源调度,还负责 MapReduce 程序运行,资源调度和计算的高度绑定耦合。
到了 Hadoop2 改成了Yarn+MapReduce 的架构,这样就保证 Hadoop 集群既能跑 MapReduce 计算任务,还能跑任何支持 Yarn 资源调度的计算任务,如 Spark,Storm 等。
大数据架构
Lambda 架构
- 同一套指标需开发两套代码进行在线和离线分析,维护复杂。
- 数据应用查询指标可能需同时查询离线数据和在线数据,开发复杂。
- 两套引擎(流+批),运维复杂
- 数据更新要 overwrite 整张表或分区,成本高
随着在线分析业务越越多,Lambda 架构的弊端越发明显,增加一个指标要在线、离线分别开发,离线指标还可能和在线指标对不齐,部署复杂,组件繁多。真是一个痛苦的时代。
Kappa 架构
使用同套引擎同时处理在线和离线数据,数据存储在消息队列上。也有其局限:
- 消息队列的容量特性使得历史数据可能无法回溯;数据可能乱序,可能对部分时序要求严格的应用造成数据错误。
- 流计算引擎批处理能力较弱,处理大数据量性能较弱。
- 从消息队列取数没有 SQL 自然,需要开发适配,开发复杂。
站在未来的当口回望
实时计算
第一代Storm
流式的MapReduce框架(很多人还没经历用过就过气了),用这种比喻说明它API的Low-Level和开发效率的低下。业务人员参与编写好比登天,设计原则和其它系统大相径庭。更多考虑实时流处理时延而非一致性保证(至多一次/至少一次语义),而一致性是其它大数据系统必备基础产品特征。
Spark
- 在内存中可执行大量计算工作,到作业最后一步才写入磁盘,通过弹性分布式数据集(RDD)实现这一目标,用户确实在Spark享受到了巨大的性能提升。泛化将多批任务串联起来,spark streaming诞生。
- storm的低阶API及非一致性保证,在这里都得到了解决,第一个广泛使用
Flink
- Exactly Once保证:故障后能正确恢复有状态计算中的状态
- 低延迟:有些应用程序需要亚秒级延迟
- 乱序数据的支持:支持乱序到达,延迟到达后,计算出正确的结果
- 流量控制:慢速算子的反压应由系统和数据源自然吸收,避免因消费者缓慢而导致崩溃或性能降低
- 完备的流式语义:支持窗口等现代流式处理语义抽象(个人觉得是伪命题)
流处理中保证高性能又保证容错是比较困难的,批处理作业失败可重新运行,因为文件可重放。流处理视图上,数据流是没有起终点的,也就是流计算是有状态的(系统要备份和恢复状态)
大数据任务类型
pie showData
title 大数据任务类型
"Batch" : 60
"Stream" : 10
"Adhoc(执行计划不重用)" : 10
"其它(ML,Graph等)" : 20
流批一体
流批一体在2020年已不火,Lambda架构还是比激进的Kappa架构存在感强。猜测有三种可能:
- 天下已定 (可能性1%)
- 批数据主流下流框架性能受挑战(工程水准够不够)
- 数据历史/资产的治理 是否高效经济?
湖仓一体化
实时数仓
三大当红国际派
基于 Lambda 和 Kappa 架构的缺陷,凸显了在大数据领域,实时数仓的建设和维护非常重要。Uber 孵化的Hudi,Databricks 孵化的 Delta lake,Netflix 孵化的 Iceberg 都在尝试解决此问题。三者均为 Data Lake 的数据存储中间层。
Hudi为了解决 uber 的增量 upserts问题;
Iceberg 诞生于Netflix, 旨在解决文件列表等云存储规模问题(当时是 S3 上存储大型 Hive 分区数据集时出现的性能,可扩展性和可管理性挑战),定位高性能分析与可靠的数据管理;
Delta 定位流批一体的数据处理
三种场景的不同造成三者设计上的差别。Delta 在数据 Merge 方面性能不及 hudi,查询性能不如 Iceberg,但与 spark 整合好,工作场景多。从字节和亚马逊的实践上看,当前上下游生态的开放性和成熟度上,对全局索引的支持,对某些存储逻辑的定制化开发接口,Hudi 暂胜一筹。如 hudi 有强大的数据摄取实用程序deltaStreamer允许你从各种来源增来摄取上游更改。
- 三者都支持数据可变更,并发控制也都支持的不错。其中 Hudi 相比较另两个还支持 Merge on Read,能更好应对流式场景,减少写放大的发生。
- 在元数据变更上,Iceberg 很有优势,其设计能进行Full Schema Evolution,可任意地改变列的位置,类型,还提供 Partition Evolution,能帮助更好地管理数据。另两个引擎,Delta 只能与 Spark 结合,利用了 SparkSQL 的 Schema,Hudi 同样直接使用 SparkSQL 或 FlinkSQL 的 Schema,在 Schema Evolution 上比较弱,只支持在最后新增列。
- 在多引擎支持方面,Iceberg 原生设计就为了支持多引擎,分层设计很好,想增加一个新的引擎时就很简单。Delta 和 Spark 绑定骄较深,移植困难。Hudi 支持多引擎,只是支持别的引擎的话,增加代码会比较多,需从底层往上垒代码
- 对后端存储的支持,Iceberg 对后端存储之要求简单的三点,不管是分布式存储还是对象存储大多数都支持。Delta 相比 Icegerg,它的 Constant Listing 是比较严格的要求,有些对象存储可能满足不了。Hudi 并未对存储有什么具体要求,只要你实现一个 Hadoop FileSystem API,就可以跑 Hudi[6]
对于数据湖,大家可能进行数据探索和开发,如果你的存储格式在并发读/并发写(包括元数据变更)上不友好,在任务编排上就会出现很大的局限性。另外最好对多种计算引擎都亲和支持,以方便拥抱技术调整,还有一点比较重要的是部署和存储选择灵活,HDFS,云托管,对象存储也支持。
多记一嘴 Hudi
Hudi 和 Hive 间的关系是相互依赖的,Hudi 作为数据管理工具,可将数据以 Hudi 表的形式存储到 HDFS中,而 Hive 可通过 Hive 表的方式对 Hudi 表进行查询和分析。可理解为 Hudi 赋能了 Hive 表增量更新和删除的能力,且相较于几种原始表存储格式有更高效的索引实现。它本质上是在大数据存储上的一个数据集,使得用户能在 Hadoop 兼容的存储上存储大量数据(其实也可以不依赖 hadoop。可以用操作系统的文件系统存储,但为了分析性能和数据可靠性,一般都搭配 HDFS),对上可暴露成一个普通的 Hive 表或 Spark 表,通过 API 或命令行可以获取到增量修改的信息,且保管了修改历史,可做时间旅行或回退。
Hudi 以两种不同的存储格式:读优化的列存格式 ROFormat,缺省值是 Parquet;写优化的行存格式,缺省值是 Avro
Doris
Doris是一个 MPP(大规模并行处理框架-Massively Parallel Processing) 架构的分析型数据库,孵化于百度的 Palo,是根据 Google Mesa 论文和 Impala 项目改写的一个大数据分析引擎「架构整合 Google Mesa + Apache Impala + ORC列式存储三种技术,通过 Mesa 实现预聚合,Impala 实现 MPP连接处理,ORC 列存储更好服务 OLAP 数据分析」,兼容标准 SQL 且完全兼容 MySQL 协议,运维部署难度不高(只有 FE:负责管理元数据、解析 SQL 生成和调度查询计划+BE:存储数据及执行 FE 生成的查询计划 两种组件)。简单易用,多副本的机制减少数据网络拷贝,将数据进行分区分桶后分发散列到各个节点实现分布式计算,亚秒级获得查询结果,有效支持实时数据分析。
支持批量数据和流式数据 load ,支持数据更新,支持聚合表和物化视图,特点是采用了预聚合技术,向量化执行引擎(ShareNothing 架构,且在数据写入时建立多级索引,将任务并行分散到多个服务器和节点上,结合单节点的多核并行处理能力,在每个节点计算完成后,将各部分结果汇总在一起得到最终结果),再加上列式存储,是一个高效的查询引擎,如果你数据量比较小,可在 Doris 里完成一站式分析。
但当数据量变大时,ETL 和分析都在 Doris 里进行时,会相互影响性能,这时势必要将 ETL 任务分摊出去,外挂湖。
Kudu
Kudu 需要单独部署集群,Hudi 则不需要,还有个关键区别是 Kudu 还试图充当 OLTP 的工作负载和数据存储,且 Kudu 虽然支持更新,但不支持增量拉取,在增量自动处理方面 Hudi要方便的多。
Kudu 于分布式文件系统抽象和 HDFS 完全不同,它自己的一组存储服务器通过 RAFT 相互通信,Hudi 则与 Hadoop 兼容的文件系统(HDFS,S3,Ceph)可一起使用。
不同于Hudi 或 Delta Lake 是作为数据湖的存储方案,Kudu 设计初衷是作为 Hive 和 HBase 的折中,同时具有随机读写和批量分析的特性。但相较于前两者,Kudu 不支持云存储,版本回滚和增量处理。
总结
新技术的出现使得数仓支持 ACID、Update/Delete、数据 Time Travel、Schema Evolution 等特性,使得数仓的时效性从小时级提升到分钟级,支持部分更新,兼具流计算的实时性和批计算的吞吐性,支持近实时场景。
但也要认识到数据湖模式无法支撑更高的秒级实时性,也无法直接对外提供数据服务,需要搭建其他的数据服务组件。
湖仓对比
| 对比维度 | 数据湖 | 数据仓库 |
|---|---|---|
| 方法论 | 事后建模(schema-on-read) | 事前建模(schema-on-write) |
| 存储类型 | 结构化/半结构化/非结构化(文件) | 结构化/半结构化(表) |
| 计算引擎 | 向所有引擎开放,各引擎有限优化 | 向特定引擎开放,易获得高度优化 |
| 成本 | 易启动,难运维管理 | 难启动,易运维管理 |
| 数据治理 | 质量低,难管理使用 | 质量高,易管理使用 |
随着数据量的增长,运维管理会越来越困难,所以有很多数据湖最终有可能变成数据沼泽(比如,大家也不知道这个数据属于谁,谁被谁来用,能不能删掉,该怎么治理),这是数据湖面临的一个问题。
大多数数据仓库建立之初要有一个有关整体数据建模的顶层设计,所以数据仓库的启动成本很高。但这种很好的顶层设计,会使数据仓库日后扩展时的运维和管理成本变得更低,长线成本优势变得非常明显。(但数仓在面对AI这种非结构化数据存在很大挑战,它几乎不支持音视图类型的数据,而数据湖可存储所有类型,更灵活更有优势)
融合流派(Data Lakehouse)
数据复杂性与管理挑战
51%的受访者报告他们有 20 到 100 个或更多的数据源,显示了数据整合和管理的复杂性。
湖仓架构通过减少数据移动和数据副本,提高了查询速度并降低了成本,大型企业预计能节省成本 75%以上,56%的受访者也觉得他们能节省 50%以上的分析成本。
体系融合
这两个体系可以说是硬币的两面,很多厂商开始考虑怎么在数据湖上应用更多数据仓库技术,反过来数据仓库厂商也希望用数据湖技术使自己更开放,这两个技术在相互学习和融合,也就造出一个新名词—湖仓一体。
一种将数据湖的灵活性和数据仓库的结构化查询能力相结合的架构,支持各种数据类型的高效存储和分析
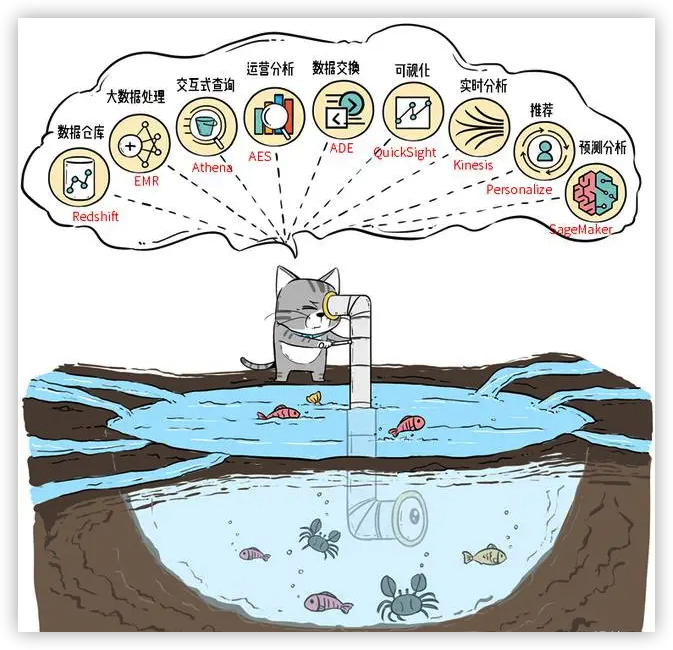
有两个流派,双方都在发展中:
- 「仓外挂湖」左边一个数据仓库,右边一个数据湖,中间以高速网络相连形成联动,这种流派的代表是AWS的Redshift。
- 另一个流派是数据湖向数据仓库演进「湖上建仓」,整体架构师在数据湖上搭建数据仓库,阿里云的Maxcompute,Databricks是代表
总结 vs 预测
大数据平台的发展在很长一段时间几乎都是以分析(BI)为轴,主流接口是SQL,侧重结构化的数据和二维关系表达的运算模式,以历史数据为主,在之上做统计和分析。
非结构化的数据处理过去一直是瓶颈,但10年前的深度学习技术突破了这一瓶颈,在过去5年中,算法类负载在数据中心里从一个很低的比例增长到10~30%,正式成为数据平台的一等公民。
说数据分析和BI侧重于历史数据总结,算法和AI具备越来越好的面向未来做预测的能力,该说法有合理性。
OLAP 查询引擎
古早实时数据探索系统的问题
第一代的实时数据探索通常是 Spark+Redis+Hbase 的方案,存在下述问题
- 流量高峰期处理延迟
- 纬度交叉分析不灵活
- 消耗资源大,碰到系统故障时,重算慢
在大内存情况下很容易崩溃,哪天一个硬件故障,一天的数据可能要重算,算一天需要十几个小时。
新质生产力对比
在传统的数据仓库架构中,ETL 是在数据仓库之外,OLAP 在数据仓库之内的,Hadoop 体系引入数据仓库领域后,大大提升了数据 ETL 处理的能力,集群的扩展能力,数据存储的稳定性,但是牺牲了数据的查询能力。
-
Kylin,Presto,Impala,Druid 都是为了解决 OLAP 查询而设计的,但这些基于 HDFS 设计的 OLAP 引擎只是加速了查询速度,未能达到令人惊艳的速度,ClickHouse 和 Doris 在速度方面更胜一筹。
-
Presto,Impala,Greenplum 在支持的 SQL 计算上更为通用,更适合 Ad Hoc 场景,然而这些通用系统往往比专用系统更难做性能优化,所以不太适合做 $QPS > 1000$ & $Latency < 500ms$的在线服务,更适合做公司内部的查询服务和加速 Hive 查询的服务。
-
TiDB 是一套 OLTP+OLAP 的数据库,但作为非独立 OLAP,分析处理能力并不理想,性能在不同场景下表现参差不齐。
当时间回到 2017 年,市场上找开源 OLAP工具就像在非洲大草原上找树一样,寥寥无几,可能只有 Druid 或 Kylin,Kylin的最佳存储引擎为 HBase,预计算查询效率出色,但预计算带来的维度爆炸会给存储带来一定压力(有 N 个维度,就会有 2N 种组合,所以最好控制好维度的数量)。Druid 也有缺点,对 Join 支持弱,组件众多需大量安装维护工作,侵入 Hadoop 的 Jar 依赖,精确去重较慢。
细说说一众引擎
Presto(适合秒级查询),Impala,Druid,Kylin(专注预计算,最初由 eBay 开发并开源贡献),Doris 和 Clickhouse(实时数据更新和高吞吐写入,但多表Join查询支持性能不好,并发较低),GreenPlum有较好的生态,但作为老将应对超大规模数据已显颓势。
Presto
Presto 是 MPP+SQL on Hadoo,它的设计和编写完全是为了解决像 Meta 这样规模的商业数据仓库的交互式分析和处理速度问题,它不是一个数据库,是一个运行在多台服务器上的分布式系统,命令行把 CLI 提交给 Coordinator 解析,分发处理队列到 Worker,将多个数据源进行合并,跨越整个组织进行分析,主要用来处理响应时间小于 1 秒到几分钟的场景。并没有使用 MapReduce,而是通过一个定制的查询和执行引擎来完成,所有的查询处理在内存中,所以性能较 Hive 快很多,但多张大表关联操作时易引起内存溢出错误。
实际体验结果:查询延迟一般,因为它是从明细层开始查询,没有任何预聚合
Impala
Impala 是 Cloudera 受到 Google Dremel 启发主导开发的 Hive 的升级品,不同于 Hive 的原始 MapDeduce 过程,提供访问 Hadoop 文件系统中数据的最快方法,但不能读取自定义二进制文件,仅限于文本文件。
Impala使用 Hive 的元数据,完全在内存中进行计算,是 CDH 平台当时首选的PB 级大数据实时查询分析引擎。通常搭配存储引擎 Kudu 一起提供服务,最大优势是点查比较快,且支持数据的 update 和 Delete。
ClickHouse
ClickHouse由俄罗斯yandex公司开发。专为在线数据分析而设计。Yandex是俄罗斯搜索引擎公司,日处理记录数”十亿级”。其从 OLAP 场景需求出发,定制一套全新高效列式存储引擎,实现了数据有序存储、主键索引、稀疏索引、数据 Sharding、数据 Partitioning、TTL、主备复制等丰富功能,用C++实现,具备向量化执行,剪枝等优化能力,具备强劲的查询性能。不依赖 Hadoop 体系(HDFS+YARN),比较擅长的地方是对大数据量单表进行聚合查询,比较适合内部 BI 报表型应用,可提供 ms 级别的响应速度。
今日头条内部用 Clickhouse 做用户行为分析,内部一共几千个ClickHouse节点,单集群最大 1200 节点,总数据量几十 PB,日增原始数据 300TB 左右
腾讯也用ClickHouse做游戏数据分析,并建立一整套监控运维体系
携程内部从 18 年 7 月开始试用,现24 年每天数据增量十多亿,近百万次查询请求
快手内部也在使用,存储总量大约 10PB,每天新增 200TB,90%查询小于3秒
ClickHouse 作为目前所有开源MPP计算框架中计算速度最快的,它在做多列的表,同时行数很多的表的查询时,性能是很让人兴奋的,但是在做多表的join时,它的性能是不如单宽表查询的。性能测试结果表明ClickHouse在单表查询方面表现出很大的性能优势,但是在多表查询中性能却比较差,不如Presto、Impala、HAWQ的效果好。
单表查询性能对比 Presto,Impala包括 Doris,确实要高很多。但 Clickhouse 没有高速低延迟的更新和删除方法,行级别的更新删除方法一般都是异步进行。
Greenplum
GreenPlum在基于PostgreSQL9.4开发,采用 MPP架构的关系型分布式数据库。其SQL支持,特性,配置选项和最终用户功能在大部分情况下和PostgreSQL非常相似。相比较,GreePlum可以使用追加优化(append-optimized)的存储格式来批量转载和读取数据,且能提供HEAP表上的性能优势。追加优化的存储为数据保护,压缩和行/列方向提提供了校验和。行式和列式追加优化的表都可以被压缩。 Greenplum的interconnect(网络层)允许在不同的PostgreSQL实例之间通讯,让系统表现为一个逻辑数据库。也包括为针对商业智能(BI)负载优化PostgreSQL而设计的特性。
提取下GreePlum和 PG 的主要区别:
- 在基于Postgres查询规划器的常规查询规划器之外,可以利用GPORCA进行查询规划
- 可以使用追加优化的存储
- 可选用列式存储,只能和追加优化表一起使用。在所有使用列式存储的追加优化表上都提供了压缩
优势
有完善的生态系统,可以与很多企业级产品集成,譬如SAS,Cognos,Informatic,Tableau等;也可以很多种开源软件集成,譬如Pentaho,Talend 等。从应用编程接口上讲,它支持ODBC和JDBC。完善的标准支持使得系统开发、维护和管理都大为方便。支持分布式事务,支持ACID。保证数据的强一致性。
作为关系型数据库产品,它的特点主要就是查询速度快,数据装载速度快,批量DML处理快。而且性能可以随着硬件的添加,呈线性增加,拥有非常良好的可扩展性。因此,它主要适用于面向分析的应用。比如构建企业级ODS/EDW,或者数据集市等
劣势
Greenplum无法对实时数据进行增量聚合计算,难支持实时数据分析,数据扩容时需进行数据重分布,需人工操作且工作量大,影响线上服务。前端采用 cognos query studio 作为自由拖拽,实现灵活查询和效率之间的一个相互平衡和制约,查询效率不会太高,业务更关心的是能出数而不是效率本身。
但在这个年代选择多了,Greenplum 已经不流行了,但在大数据体系成熟之前,在 10 年之前,还是有很多公司引入其做基础数据仓库,不乏银行金融机构,淘宝,支付宝等。
Druid
Druid由 MetaMarkets(一家广告数据分析平台公司) 开发并于 2015 年开源,创建的最初意图是为了解决查询延迟问题,毕竟使用 Hadoop 来实现交互式实时查询分析很难,Druid 在这方面提供了以交互式访问数据的能力,并权衡了查询的灵活性而采取了特殊的存储格式。它的核心架构吸收结合了数仓,时序数据库及检索系统的优势。
其功能介于 PowerDrill 和 Dremel 之间,几乎实现了 Dremel 的全部功能,且从 PowerDrill 吸收了一些有趣的数据格式,在二者基础上增加了一些新特性,如为局部嵌套数据结构提供列式存储格式,实时摄取[收录事件]和查询(事件创建后毫秒/秒内查到),高容错的分布式体系架构等,每天能处理数十亿事件和 TB 级数据。其应用最广的是广告分析(点击流分析),广告监控及网络监控等,最适合应用于面向事件类型的数据,数据插入频率较高,但较少更新数据。
多数查询场景为聚合查询和 groupby分组查询,数据具有时间属性(Druid 对时间做了优化设计),需要对高基维度数据列(URL,用户 ID等)进行快速计数和排序,需要从 Kafka,HDFS,对象存储中加载数据。无论何种查询,历史节点都会先将相关 Segment 数据文件从磁盘加载到内存,然后再提供查询服务,历史节点的查询效率受内存空间影响很大,内存越大,需从磁盘加载数据的次数就越少,查询速度就越快。
目前 Druid 在实际应用中遇到的最大问题是缺少支持精确的基数计算的数据结构。Druid 的架构组件比较复杂(协调器,历史节点,实时节点),部署和运维成本较高。对 SQL 的支持不够全面,某些复杂查询可能要自定义实现。
Druid 有三个外部依赖:Mysql 存储各种 metadata,存储 Segment 的载体(本地磁盘,NFS,HDFS,S3 均可),Zookeeper 管理当前 cluster 的状态,如哪些 Segment 由Real-time node 移到了Historical nodes。
不适合的场景
如果你需要对现有数据进行低延迟的更新操作,就不太合适用 Druid 了,它支持流式插入(流数据摄入后会以 Index 形式保存在内存中,定期将 Index 序列化成 Segment 文件持久化到可靠存储中-如 HDFS),但不支持流式更新(更新通过后台批处理作业完成)。批数据摄入则会直接生成 Segment 存储,供服务加载使用。
其查询并发有限,不适合 OLTP 查询,不支持 join 使得只适合处理星型模型的数据,实时数据要能容忍丢失数据。
OLAP 的实现模式
作为一个 OLAP 数据库,需要支持类似上卷,切块,切片,下钻等操作,但不适合明细查询(根据某主键 id 定位唯一数据的任务),常见的 OLAP 数据库实现方式有以下几种:
- 数据检索引擎,如 ES。可存储结构化/非结构化数据,同时具备明细查询和聚合查询能力,但其索引类型并不是针对聚合分析设计的,所以聚合查询方面开销较大,其次,ES 不但要保存所有原始数据,还需要生成较多索引,所以存储空间开销会更大,数据写入效率较 Druid 会差一些。相比较,Druid 只能处理结构化数据(预定义 Schema),由于进行预聚合,所以 Druid 抛弃了原始数据,导致其缺少原始明细查询能力,若关闭预聚合,又会丧失 Druid 的优势。
- 预计算+KV 存储实现,如 Kylin。缺点是需在预处理中处理预设的聚合逻辑,故损失了查询灵活性,且面临数据过于膨胀的情况。
- SQL on Hadoop 引擎:如 Presto,SparkSQL
能力对比
| Kylin | ES | SparkSQL | Druid | Presto | Impala | |
|---|---|---|---|---|---|---|
| 离线查询 | Y | Y | Y | Y | Y | Y |
| 实时查询 | N | Y | N | Y | N | N |
| 丰富的 SQL | Y | N | Y | Y | Y | Y |
| 百亿数据集 | Y | Y | Y | Y | Y | Y |
| 聚合亚秒级响应 | Y | N | N | Y | N | N |
| 精准去重 | Y | N | Y | N | Y | Y |
| 表关联 | Y(弱) | N | Y | N | Y | Y |
相较于 Kylin,Druid 没有模型管理和 cube 管理能力,Kylin 无法提供实时查询
相较 ES,Druid 优势在于聚合计算,ES 优势在于查询明细
性能特性比较
简单查询
在简单查询场景(命中索引或物化视图-预聚合数据),这样的查询通常出现在「在线数据服务」的企业应用,并发查询量大,对响应时间要求一般是 ms 级别,最合适的是 ES,doris,druid,kylin 这些
- druid、kylin的 QPS <1000
- Clickhouse的 QPS < 100
- ElasticSearch QPS > 1000
- 在亚秒级别响应的只有 es,druid,kylin,clickhouse。Hive 在落在分钟小时级,其它在秒级。
quadrantChart title 简单查询吞吐能力 x-axis "毫秒" --> "分钟小时" y-axis "几十" --> "几千" quadrant-1 "高QPS高时延" quadrant-2 "高QPS低时延" quadrant-3 "低QPS低时延" quadrant-4 "低QPS高时延" Druid:[0.3,0.6] Kylin:[0.3,0.55] ElasticSearch:[0.2,0.85] Clickhouse:[0.32,0.2] Impala+kudu:[0.42,0.57] Presto:[0.42,0.52] FlinkSQL:[0.45,0.32] SparkSQL:[0.45,0.21] Hive:[0.75,0.3]
复杂查询
复杂查询场景,指复杂聚合查询,大批量数据 scan,在 ad-hoc 场景中,往往用户不能预先知道要查什么,更多是探索式的。
quadrantChart title 复杂查询吞吐能力 x-axis "毫秒" --> "分钟小时" y-axis "几十" --> "几千" quadrant-1 "高QPS高时延" quadrant-2 "高QPS低时延" quadrant-3 "低QPS低时延" quadrant-4 "低QPS高时延" Druid:[0.65,0.30] Kylin:[0.65,0.25] ElasticSearch:[0.65,0.35] Clickhouse:[0.48,0.2] Impala+kudu:[0.42,0.57] Presto:[0.42,0.52] FlinkSQL:[0.75,0.19] SparkSQL:[0.75,0.14] Hive:[0.9,0.21]
ES 出列单看
ES,Druid,Kylin 都是单轮的 MapReduce,中间结果结果存储在内存中,通过网络直接交换,而不是像典型的 多轮MR 每次 shuffle 要先落盘。
用 ES 做 OLAP 引擎,有几项优势:
- 查询模式简单的场景高 QPS,低延迟,过滤条件多。ES 底层依赖 Lucene文件格式,可把 Lucene 理解为一种行列混存的模式,在查询时通过 FST,跳表加快数据查询。
- 但单轮的 MR模式(单节点汇聚)若 Reduce 数据量较大(数据量较大或进行扫描聚合类查询时),由于 ES 是单节点执行,可能会非常慢。
- 集群自动化管理能力非常强(shard allocation,recovery),集群,索引管理和查看 API 非常丰富。
多记一嘴 Druid
很多数据仓库产品都是以『批处理』为基础,这导致记录指标时的时间与进行分析时的时间间出现延迟。
-
指标是衡量事物发展程度的单位和方法,通常需要经过加和、平均等聚合统计才能得到。如 PV,UV,页面停留时长,用户获取成本
-
维度是事务现象的某种特征,如性别、地区,时间,版本,操作系统都是维度。Druid 只会预计算最细粒度的维度和时间结果,减少维度爆炸问题,是一种比较平衡的方式。
Druid 之所以能在 OLAP 家族中占一席之地,除了依赖 MPP 架构外,还运用了四点重要的技术
- 预聚合:减少数据存储于避免查询时不必要的计算
- 列式存储
- 字典编码:有效提升数据压缩率
- 位图索引:让很多查询转化成计算机层面的位计算,提升效率
存储层是 Druid 的核心组件,用于存储和管理数据,其用列式存储格式来优化查询性能和压缩数据大小,存储层由多个数据分片组成,每个分片都包含了特定时间范围内的数据,数据分片可水平扩展和复制,以实现高可用性和高吞吐量。
使用 Druid 过程中,维度不要太多,维度数据导入将十分耗时。磁盘适用固态盘,这样你的查询速度才稳定的快。
时序数据库特性
Druid 是针对时间序列数据提供的低延时数据写入及快速交互式查询的分布式 OLAP 数据库。时间列是 Druid 数据模型的核心组成部分,它允许数据按时间进行排序,分割和分片存储,以支持高效的数据查询,且可将数据按固定时间间隔(小时,天,周)划分为不同的桶,每个桶存储一个时间段内的数据。其与典型的InfluxDB、OpenTSDB部分特性类似,这些时序数据库具备一些共同特点
- 一是通过内存增量所有让数据写入即可查
- 二是下采样或 RDD操作减少数据量,Druid 在数据写入时就会对数据预聚合,进而减少原始数据量。
- 三是可能会支持 SchemaLess,InfluxDB中,用户可任意加 tag,InfluxDB 可对新增 tag 进行聚合查询,但 Druid 在这点上跟 InfluxDB 略有差异,Druid 需预定义 Schema,Schema 数据打包在最后形成的数据文件中,也就是说过去和未来数据的 Schema 可以不同,不同 Schema 的数据可共存,固然 Druid 不是 Schemaless 的,但调整也是比较灵活的
在时序数据上,ES 也有类似功能,提供了全文检索的模式,并提供访问原始事件级数据,也提供了分析和汇总支持,但根据研究,ES 在数据获取和聚集上资源消耗比在 Druid 高,Druid 侧重于 OLAP 工作流程,以较低的成本设计了聚集和获取的高性能方案(亿级百列数据查询时间是 mysql cluster 的1/100~1/10),提供了结构化事件数据的一些基本的搜索支持,更偏重于数据汇总分析。
为了性能,你开启了预聚合 rollup,这会带来信息量的丢失,因为 roll-up 的粒度会变成最小的数据可视化粒度。如果以分钟粒度进行 roll-up,那么入库后能查看的数据最小粒度即为分钟级别。
Segment设计
Segment 是 Druid 的一个关键抽象,是一种不可变(但有版本控制)数据结构。Druid 可看作是 Lambda 的第一个实现。
Segment 的不可修改性简化了 Druid 的实现,但若你有修改数据的需求,重创建 Segment的 Bitmap indexing 过程是比较耗时的。其能接受的数据结构相对简单,不能处理嵌套结构的数据。
Druid 用 Lambda 架构分别处理实时数据和批量数据。数据存储在 Datasource 中,类似 RDBMS 中的 Table,每个 Datasource 中按时间划分,每个时间范围称为一个 Chunk(一般一天一个 Chunk),在一个 Chunk 中数据根据维度的Hash 或范围分成一个或多个Segment,每个 Segment 都是一个单独文件,通常含几百万行数据,这些Segment 是按时间组织的,所以在按时间查询时,效率非常高。
实际上,Datasource 和 Chunk 都是抽象的,Druid 底层存储就是 Segment,一个 Segment 生成后就无法被修改,只能通过生成一个新 Segment 来替代旧的。Segment 的命名规则可帮助快速找到需要查的 Segment 文件。不同列的数据都单独保存一个文件的话,会产生很多小文件,严重影响文件系统读写性能,因此每个字段数据生成好后,会以二进制拼接的方式合成一个文件以提升性能,在逻辑上,不同列的数据存储是分开的。
在数据摄取准备时,要敲定查询的最小粒度,如 hour,查询最小粒度要<= Segment 分块文件粒度
Druid 使用 Segment 时会以多级缓存的方式使用,除了可靠存储,还会在内存中及服务器硬盘上加载 Segment 作为缓存。开启预聚合(rollup)特性的 Segment内部也会不一样,可大幅减少数据存储量,提升查询效率,关闭 rollup 则 Segment 中会保留写入的原始数据。
让 Druid 在繁重的查询压力下保持良好的操作性能,应让 segment 文件大小在 300mb 至 700mb 之间。其在设计之初,为了追求亚秒级的 OLAP 能力,对精准去重计算,不支持,只提供近似查询。在实时要求程度不高的情况下,可通过时间换空间的方式,对需要计算的字段做 group by 查询,然后 count(1)实现精确去重,
行数据结构剖析
Druid 中每一行包含 3 部分:时间戳,维度和指标。
- 时间戳就是该条数据产生或保存的时间,主要作用有划分 Segment,按照某种时间粒度预聚合数据等。
- 指标就是一些整数或浮点数值,也可能是复杂数据结构如 HyperUnique,用来在查询时聚合得到结果。
- 维度相对复杂点,因为在查询时要支持 filter,group by 操作,每列维度值会保存 3 个数据结构来记录(如10 行数据,某列数值取值如下)
$$
\begin{bmatrix}
A\
A\
B \
C \
B \
C \
D \
C \
D \
D \
\end{bmatrix}
$$
- 取值字典:每个值映射为一个 ID,可理解为独热编码表
1 | "A":0 |
- 10 行/每一行取值的 ID:行数据的独热编码表示。用于支持 group by 和 TopN 查询。
1 | [0,0,1,2,1,2,3,2,3,3] |
- 每个取值对应的 Bitmap(对 AND 和 OR 操作速度非常快),在 Segment 存储中会以 concise/roaring 方式压缩。独热码表值在此列的位置分布。
1 | 0:[1,1,0,0,0,0,0,0,0,0] |
位图索引再举例
举一个更直观的例子,如下表数据
| 时间戳 | 维度列 | 指标列 | |
|---|---|---|---|
| dt | loc | item | amount |
| 2022-01-01 | 北京 | 书 | 100 |
| 2022-01-01 | 北京 | 电脑 | 200 |
| 2022-01-01 | 上海 | 电脑 | 300 |
| 2022-01-01 | 广州 | 手机 | 400 |
| 2022-01-01 | 杭州 | 水果 | 500 |
| 2022-01-01 | 北京 | 书 | 600 |
Druid 将如上数据结构构建位图索引,来实现快速查找
| 原始值 | 列值编码 | Bit | m | a | p | 位 | 图 |
|---|---|---|---|---|---|---|---|
| 北京 | 0 | 1 | 1 | 0 | 0 | 0 | 1 |
| 上海 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
| 广州 | 2 | 0 | 0 | 0 | 1 | 0 | |
| 杭州 | 3 | 0 | 0 | 0 | 0 | 1 | 0 |
| 书籍 | 4 | 1 | 0 | 0 | 0 | 0 | 1 |
| 电脑 | 5 | 0 | 1 | 1 | 0 | 0 | 0 |
| 手机 | 6 | 0 | 0 | 0 | 1 | 0 | 0 |
| 水果 | 7 | 0 | 0 | 0 | 0 | 1 | 0 |
1 | select sum(amount) as totalamout from table where loc="北京" and "item"="电脑" |
那么根据位图,查询条件就是(110001)& (011000)= (010000)所标 1的行,也就是第 2 行。
设计讨论
Druid vs Impala
Druid 和 Impala 的比较基本可归结为需要设计什么样的系统。
-
Druid 被设计为一直在线的服务(所以其容灾,扩容再平衡都做得很完备, 各种nodes挂掉都不会使得 Druid 停止工作,但状态会无法更新),可获取实时数据。在查询速度方面,Druid 是列存储方式,数据经过压缩加入到索引结构中,"压缩"增加了 RAM 中数据存储能力,能使 RAM 适应更多的数据快速存储。支持时间序列和 group by 样式的查询,但不支持 join。
-
Impala 可认为是 HDFS 之上的后台程序缓存层。Impala 基于 HDFS 或其它后备存储,限制了数据获取的速度。支持 SQL 样式的查询。
Druid vs Kylin
Druid 是 OLAP 计算+存储二者一肩挑设计,Kylin 是一个离线预处理框架,依赖 Spark 和 YARN 做计算,然后用 Hbase 保存预处理结果,而后进行展示。它们二者都对 HDFS 有依赖,Druid 只把 HDFS 当做远程离线存储,但实际计算过程并不使用。而 Kylin使用的是 Hadoop 技术栈,中间计算过程和最后计算结果里面都会用到 HDFS。
Druid 有灵活的预聚合能力,可利用 HyperLogLog 算法做多维的 UV 聚合,而 Kylin 则是使用强大的位图计算,做了精确的 UV 计算能力。
新的Topic与期待
全频谱可平衡支持
新一代数据平台系统需要形成一个从离线到实时的全频谱计算能力,在
- Data Freshness
- Resource Costs
- Query Performance
的不可能三角里给用户提供多种不同平衡的选择。面向未来的系统,应能做到一套系统一套资源,针对上述三个方向的不同平衡点,为用户提供多种选项,实现从离线到实时的全频谱。
数据网格
Data Mesh 是一种数据管理方法,强调数据的分布式架构和以业务领域为中心的数据所有权和治理权,促进数据的可访问性和质量。从侧面也反映了以中央IT团队来管理数据搞不好。
- 数据量过大或中央数据管理人员对数据不够了解,那么数据湖可能无法确保数据质量。数据网格架构的基础理念是将数据视作有价值的产品,那么数据的质量和完整性就成为数据管理的重点。
- 将企业内特定数据集的所有权和职责,分散至具备专业知识的用户(能深入了解并充分利用这些数据),同时通过标准化和自动化来保证整体的一致性和互操作性,发挥数据的价值。
- 另外数据湖的集中式架构,数据检索流程和程序一直较复杂,很容易出现瓶颈,大量整合数据的管控工作全压到了一个 IT 团队肩上,随着这些数据量和数据检索需求的增加,这些IT 团队会不堪重负,合规任务也可能会被仓促了事,引入潜在的风险和损失。
stateDiagram-v2
state1:面向领域的所有权
state2:数据即产品
state3:自助式数据平台
state4:联邦计算治理
state1 --> state2:防止数据孤岛
state1 --> state3:赋能领域团队
state1 --> state4:增加参与度,减少领域孤立
state2 --> state3:降低所有权成本
state2 --> state4:通过互连数据产品获得更高阶价值
state4 --> state3:网格级别一致可靠的策略执行
note left of state2 : 产品思维应用于数据管理:可发现、可理解、可信赖
note left of state3
支持去中心化数据管理
简化数据产品创建和使用过程
end note
note right of state4
通过自动化和计算实现政策执行
平衡域自主性和全局互操作性
end note
数据安全
数据本身已经成为一种资产,有非常好的资产变现和产生额外价值的能力和需求。同时,数据很可能涉及隐私泄露,这就形成了有关数据安全,隐私保护和数据共享的矛盾。在隐私和安全的情况下做到更好的数据共享和变现成了新热点。
数据安全不仅仅是一个权限问题,还涉及很复杂的系统架构,包括权限管理,用户隔离,存储加密,异地备份,敏感数据/风险行为的识别。
安全共享这个方向包括两个核心场景:一方数据对外共享,多方数据共同计算。第二点是多方的数据交叉计算或者叫联邦计算。这里面包含两项核心技术,一个是基于隐私计算的数据交互,一个是基于联邦学习的数据交互。不论是一方域内多租的安全模式,还是跨域多方的安全共享模式,目前都是领域热点。
IOT 时代的不同
目前的大数据系统处理的数据主要是人的行为日志,如浏览记录,手机上对App的点击操作等,都会以日志形式传到系统中,反馈给推荐系统,广告系统。
后续接入网络的硬件设备的数据慢慢会超过人的数量,IOT数据处理也会成为一个热点。但大多数时候设备数据并没有太多意义和价值,只有出问题的时候数据才会产生波动,这种情况下如何有效收集设备产生的数据,海量数据无法全量上云,需要在端侧做一定处理,就成了新的需求,也就是端云协同,是IOT的特点,不过也实在没什么新鲜,没有技术难度。
DW Automation
- 国内最大的互联网公司,内部数据量均在EB级别,作业量每天百万级别以上。
- 主流客户其实都在PB级的数据规模,有些在百PB级别。
面对这么大的数据规模,传统DBA以人为轴来开展数据管理和优化的方式不再胜任。这种复杂的数据组织和优化需更多的基于AI的自动化技术来完成。如通过机器学习自动进行数据分层,依据访问的统计判断什么样的数据更重要,那些作业可放在冷存储上。
几朵乌云
- 计算引擎的多样化,最终能否诞生一套onesize4all的引擎满足多样的计算需求,兼顾通用性和效率
现在大家几乎还是通过拼接不同引擎来搭建自己的计算平台,如Spark做批处理,Flink做流处理,Clickhouse做交互分析,再复杂点,可能还要部署Hbase做KV查询,用ES做文本检索。虽每个单独产品已比较成熟,但整个系统复杂度非常高,这里面就蕴含着标题的期待。
- 基于开源自建还是选购企业级产品
开源软件免费,但需要独立的团队去支撑这一大数据平台的部署和运维,带来相对较高的维护成本(一个简答的公式是:对于百台规模的平台,基于开源软件自建的总TCO=物理硬件成本+开发维护人力成本=物理硬件成本*2)。
头部的技术公司,规模较大,人力边际成本低。非头部企业直接购买SAAS化企业级平台,综合成本更低,享受更好的性能,安全性,稳定性和兜底能力。当然另一面就是技术黑盒和高改造成本(需平台厂商来做)的问题。
Snowflake开箱即用全托管平台大受欢迎,Databricks以开源生态为主线也形成广泛客户群体。组装还是直接买笔记本,答案在客户手中。
- 关系模型外,是否会发展处其它主流计算范式
数据库数仓已发展40+年,主流计算范式就是二维关系表达,近10年,深度学习带来新的计算方式,有没有更新一代会产生?
图计算当前最被看好(点边模型)。但数据库技术发展过程中也诞生了图计算模式,且发展多年,但目前仍不是主流,但随着图学习(graphembedding)的兴起,是否会焕发新生,值得期待。
Other
大家都说软件工程师,软件产业,但需要从 Code/Program观念转变成 Data 观念,在做任何设计和开发时,要把 Data 放在第一位,这样才是 Information Technology 行业。
海量数据一直在增长,但我们应想办法控制下来,未来的趋势要考虑缩小海量数据,而不是任凭它扩张。
太多初创企业陷入错误的逻辑:大数据=非结构化数据=hadoop,非结构化和半结构化数据的利用是呈现了爆炸式增长,但也要注意到,结构化数据的使用上,也出现了指数式增长。
搞起来了,自有人会来光顾。这是错误的观念,想用大数据创业,业务专长必须有,同时技术也必须保证是尖端的,这些都是普通商户所缺乏的,如何帮助非技术型用户在其日常工作中轻松使用数据才是问题的关键。
参考
- 1.Segmentfault 简单认识 KMV Sketch 估算算法 ↩
- 2.CSDN 开源 OLAP 技术架构对比 ↩
- 3.51CTO 数据湖三剑客对比 ↩
- 4.腾讯云 Druid Segment存储格式 ↩
- 5.腾讯云 解读数据架构的2021 ↩
- 6.腾讯云 基于 Iceberg 扩展 Doris 数据湖能力的实践 ↩
- 7.搜狐 主流开源OLAP系统的分类及核心技术点 ↩
- 8.搜狐 主流开源OLAP引擎大比拼 ↩