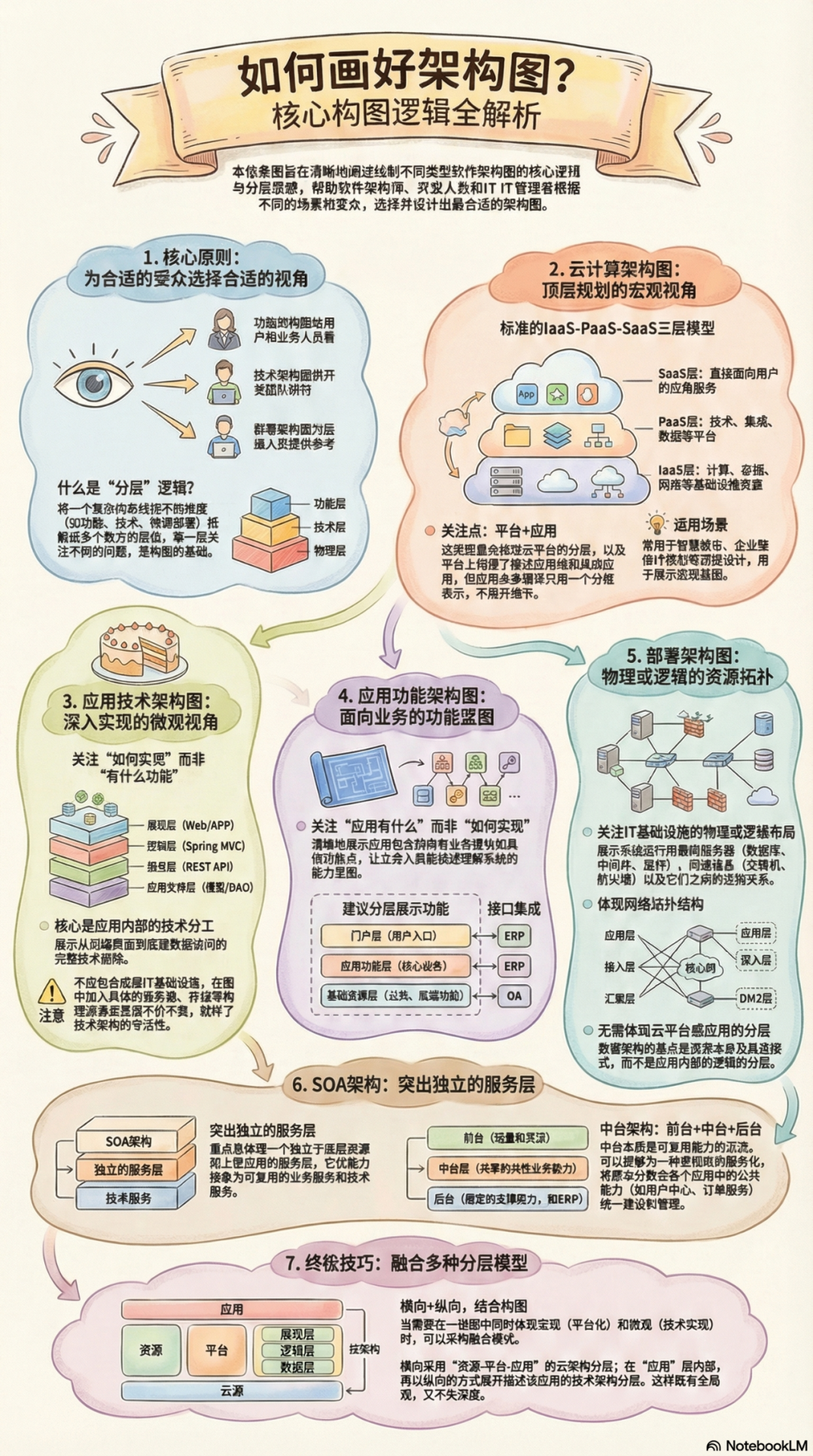
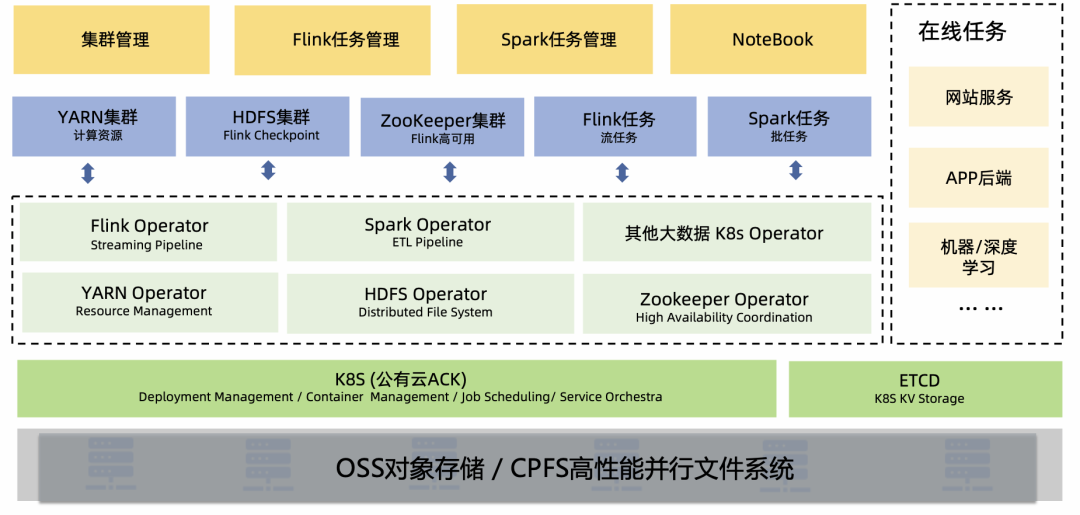
云原生基座下的大数据

云原生基座下的大数据
DiffDay
存算耦合架构回顾
最早的 Shared-Disk 架构主要是通过独立定制网络 NAS 于存储架构来实现第一代的存算分离架构,性能好但成本较高(采用网状通道技术交换机连接存储阵列和服务器主机,建立专用于数据存储的区域网络), 可扩展性较差(ScaleUp)
过去十几年 Shared-Nothing 架构,可以通过普通硬件实现类似高成本数据存储阵列所实现的效果,性能好且性价比高,有一定的可扩展性(ScaleOut)。可通过普通硬件实现类似高成本数据存储阵列所实现的效果。过去由于网络带宽的限制,我们习惯性的把计算和存储偶合在一起,以减少网络传输的压力.
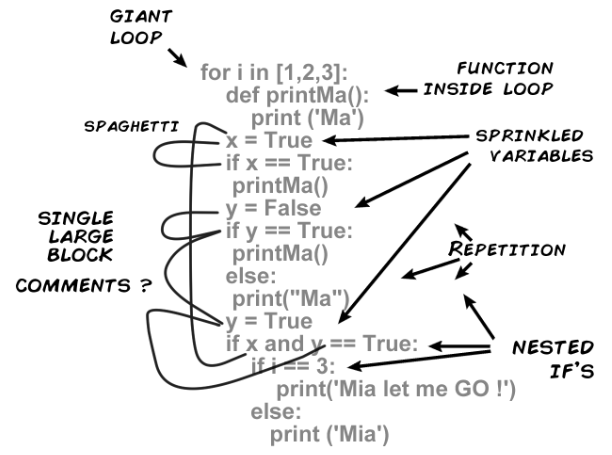
Hadoop的三元老
- MapReduce负责计算
- YARN负责资源调度
- HDFS负责存数据
发展最迅速的事计算组件这一层,业界在计算上面各显神通,造出了一大堆轮子,有MapReduce,Tez,Spark这样的计算框架,Hive这样的数据仓库,还有Presto,Impala查询引擎,各种各样的组件。配合这些组件的还有像sqoop这样的数据流转采集组件也很丰富。
然而存储在问世十年后,还是HDFS一枝独秀,组件都是面向HDFS去设计的。
如Hbase,在写 WAL log 的时候就深入利用了HDFS 的一些很内核的能力,以达到一个低时延的写入
Spark 也提供了数据亲和性(Data Locality)的能力,这些都是HDFS 提供的一些特殊的 API
HDFS自身架构的约束
HDFS本身也有局限,NameNode不能分布式扩展,限制了单机群管理文件的数量。当NameNode的资源占用较多,负载高的时候可能会触发FullGC,影响整个集群的可用性。这也是HDFS高负载集群一直以来的痛点。
根据运维经验,在3亿文件以内,运维HDFS还是比较轻松的,3亿后复杂度就会明显提升,峰值在5亿左右,就达到单集群天花板了。
文件量更多,需要引入HDFS的Federaton联邦机制,增加了很多运维和管理的成本。
Hadoop组件生态碎片化
另外Hadoop生态私有化部署,集成新的计算和存储技术,也有不小的碎片化难度。Hadoop的组件经常和HDFS和YARN的版本有严格适配要求,很多新的大数据组件不适配老的Hadoop,而升级Hadoop又会造成其它组件的生效。
云厂商为了与现有Hadoop组件适配,一方面要去改造组件和对象存储之间的connector,一方面给上层组件去打patch,验证兼容性,是不小的工作量。所以公有云提供的大数据组件包含的计算组件也是有限的,一般只含Spark,Hive,Presto三个常用的,且还只包含少数几个版本。
硬件的局限
Hadoop设计之初是一个存算耦合的架构,一个不可忽视的原因是网络通信和硬件的局限。
2006年Amazon才发布第一个云服务,机房里当时最大的问题是网卡,06年刚开始千兆,百兆还是主流。此时大数据搭配的磁盘,吞吐大概50MB/s,换算成网络贷款就是400Mbps,一个节点8块盘,吞吐都跑起来就需要几千Mbit传输了,可网卡最早也就1Gb,每一个网络节点带宽根本不够,故要让计算靠近存储。
数据处理任务从远程物理机读取数据开销大,故以数据为中心,将数据处理任务迁移到数据所在的物理机上,能有效降低网络贷款,保证整体性能,此即为存算一体的大数据技术架构。
存算分离悄悄起了变化
企业数据增长很快,但算力需求增长没那么快
- 数据生产出来,不知道怎么用。但考虑到未来会用,企业都先把数据尽可能存起来,再去挖掘价值
- 存算耦合的硬件拓扑结构给扩容带来一个影响。数据节点还负责计算,故CPU和内存配置也不能太差。机器都是计算和存储配置平衡的机器:足够的存储容量+等量算力
- 这样扩出来的算力,对企业来说造成了很大的浪费,资源利用率不平衡
- 万兆网卡普及了,有些AI场景有100Gb网卡(10w兆),带宽提升明显,磁盘吞吐提升到了100MB/s,一个万兆网卡的实例,可差不多支持12块盘峰值吞吐,对大部分企业来说已够用,网络传输瓶颈基本不存在了。
- 软件也在变化,算法和存储格式减少了要传输的数据量(压缩算法+列存储格式),IO瓶颈在合力作用下在弱化,存算分离可行性在得到保证
最初的尝试
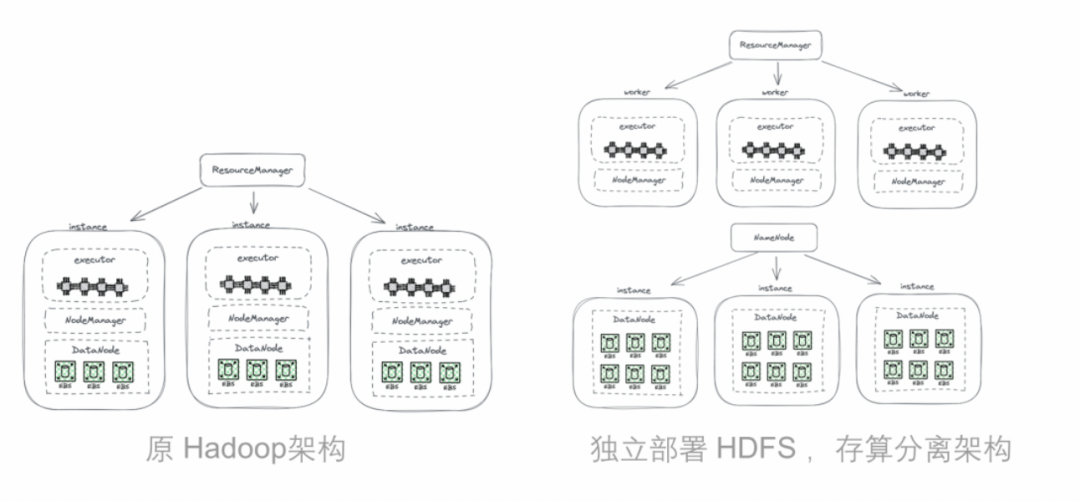
YARN 会在节点上布一个 Node Manager的进程。有了 Node Manager 之后,YARN 就会认为 HDFS DataNode 的节点,在其管理范围之内,当需要计算任务可以分发到这个节点上来完成
最初的尝试(2013 年在 Facebook )来自于将HDFS与负责计算的worker分开部署(这样没引入新的组件),DataNode节点不再部署NodeManager,这样不再把计算任务发送到DataNode节点上,计算要用到的大数据都通过网络来传输,用万兆网卡去支持。
尽管HDFS最巧妙的数据本地性设计被舍弃了,但给集群配置带来极大便利
通过实验此改造,对整个平台性能的影响仅是几个百分点[3],2%
云厂商助力
云计算厂商所提供的基础平台能力基本上解决了运维稳定性风险,改造周期长,资源使用成本的问题。将整体存算分离改造的复杂度明显降低,可行性提升。
- 多租户资源共用机制(网络/存储作为基础设施共用), 以降低支撑单用户的成本,有边际成本下降效应
- 托管了运维复杂性问题:屏蔽网络,安全,稳定性风险,搭建周期长等难题
从技术到成本的解决,让工程师更多尝试在公有云标准 IaaS 环境下不断改进大数据存算分离的技术方案,无论是数据湖存储加速还是缓存加速等等

云原生时代
以容器化和K8S为代表的云原生时代技术,已经引领一整套新的生态全景,涵盖10多个技术领域,如消息流处理,调度和任务编排,数据库等。在新技术和云平台的加持下,大家简便的享用着[分布式,弹性,存算分离(多副本容灾),资源隔离]等诸多技术福利,简直不要太幸福,另一方面,新的趋势也在催生一些旧的流行中间件,出现新竞品,如Pulsar之于Kafka。
2021年,Spark 3.1正式支持了K8S,Kafka也发布了能运行在K8S上面的版本,这两个事件也表明大数据平台的云原生化已是大势所趋。按这个趋势,Hadoop也会迁移到K8S上,MapReduce被Spark替代,Yarn也被K8S替换,最坚挺的HDFS也在出现对标替代方案。
资源调度的统一
YARN Resource Manager负责集群中所有资源统一管理和分配,它接收来自各节点(Node Manager)的资源汇报信息,将资源按一定策略分配给各个应用程序,功能起始和K8S Scheduler功能非常类似
不同场景需要的存储空间和算力配比不一样,造成集群资源浪费。算力需求也存在波峰波谷,不同业务对运行环境要求不同。Spark应用序绑定spark集群运行,web类型需实例快速水平扩展
通过统一平台来混合部署提升资源利用率的需求强烈,容器技术的出现,给了IT行业统一运行环境的梦想和能力。Build Once,Run AnyWhere
统一的Infrastructure平台能支持多种计算资源统一调度能力,如AI的GPU,web业务的cpu,大规模容器集群管理,K8S已是无可争议的事实标准
针对K8S自带的资源调度器依次调度策略,不适合AI和大数据场景的问题(这些计算任务包含的容器想要的是,要么同时都成功,要么就都别执行,否则等于白跑),也有了增强型调度器Valcano(尤其是总体资源需求>集群资源时,依次调度存在的问题很明显),Valcano解决了Gang Scheduling的问题,要么都成功,要么都别调度,基本可用来解决死锁问题,还提供多种调度算法,满足各种复杂场景需求,提高资源利用率。
对象存储的基座
HDFS上云碰到的矛盾
企业自建大数据时,一般使用裸磁盘搭建HDFS,为了解决裸盘损坏的风险,HDFS设计了多副本机制保证数据安全性和可用性。数据上云,云提供给用户的是有多副本机制存储的云盘,直接用云盘就成9副本了,成本上升之余大量浪费资源
云也会提供一些有裸磁盘的机型,但这类机型往往很少。云盘可以随意配置,但有裸盘的机型只有寥寥几款,选择余地不一定能匹配企业集群需要。
况且你用裸盘,云的开箱即用,弹性伸缩按量付费这类优势,都被放弃了。自己创建机器,手动部署和维护,自己监控和运维,还不能方便的扩容。
对象存储出位
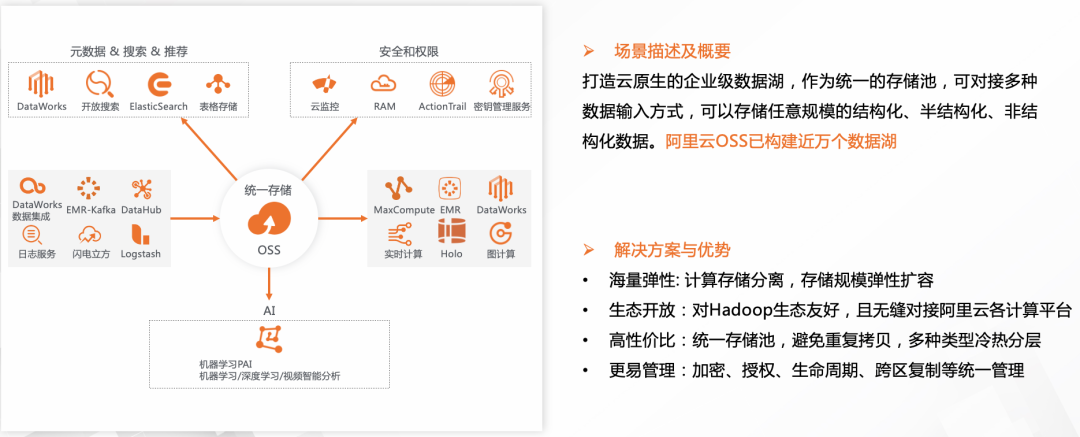
随之云计算成熟,多了一种对象存储作为选择,不少云厂商都在尝试往对象存储替代HDFS的方向去发展
- 采用EC纠删方法,实现存储优化,低成本高可用,优于HDFS三副本
- 开箱即用免运维,按量付费无需规划
- 也支持海量中小文件,对非结构化数据分析场景较有用
对象存储在并发访问的支持,前端应用的调用方面,默认高可用,及采用成本可控的分布式架构,相比HDFS文件系统,块存储和NAS存储有很大优势,因为是云端存算分离架构的主流存储底座。(阿里oss宣传冷热分层存储,整体存储预估下降成本20%)
兼容(以JuiceFs举例)
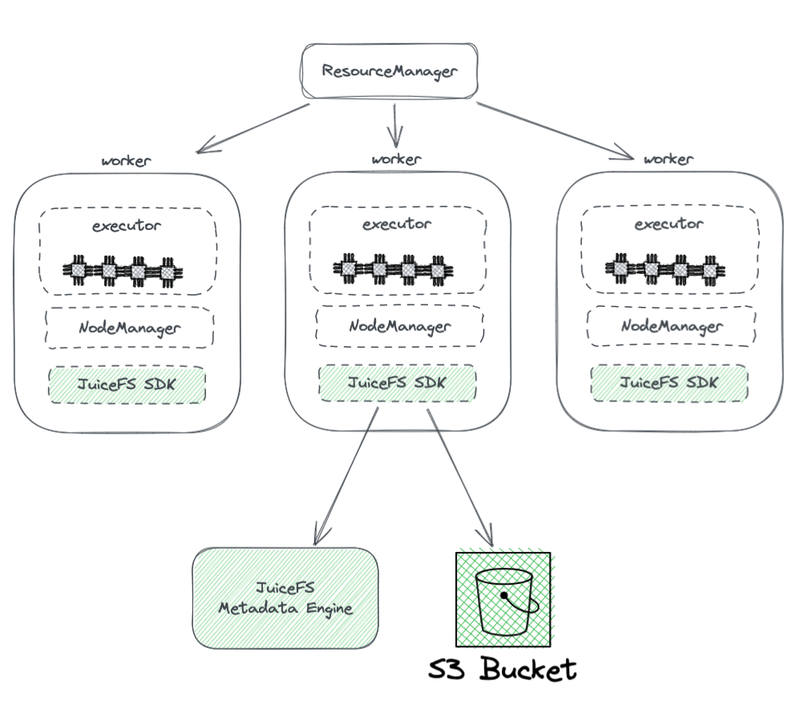
JuiceFS Hadoop SDK:部署在执行节点上,SDK完整兼容HDFS
兼容POSIX API,HDFS在设计时就是简化版的POSIX
得益于Hadoop的设计,在一个Hadoop集群里,可配置多个文件系统,JuiceFs可以和HDFS同时使用
JuiceFS Metadata engine:相当于NameNode,文件系统的元数据信息存储地。
S3 bucket:等同于DataNode,看成海量磁盘来用,它会管理好数据存储和副本的相关任务。
对象存储的原生弱项
- 文件listing性能比较弱(对象存储没有树形结构,是扁平的,当文件数量众多,前缀匹配搜索的性能比树形结构差),可listing又是文件系统中一个最基础的操作
- 没有原子rename操作,影响人物稳定性和性能(用新文件/目录名,作为key复制旧对象,此时会发生数据拷贝,一次copy和一次delete)
- ETL计算模型中,每个任务将结果写入临时目录,整个任务完成后临时目录改名正式目录即可。在常规文案系统中此操作是原子的,速度快,有事务性保证,可由于对象存储没有原生目录结构,处理rename是一个模拟过程,会包含大量系统内部数据拷贝,耗时比想象的多
- MR过程会产生大量的list和rename操作,相比原生HDFS,对象存储在大数据分析效能会有明显的性能损失
- 最终一致性机制会降低计算过程的稳定性正确性
- 多个客户端在一个路径下并发创建文件,这时调用 List API 得到的文件列表可能并不能包含所有创建好的文件列表,而是要等一段时间让对象存储的内部系统完成数据一致性同步,List在ETL 数据处理中经常用到,最终一致性可能会影响到数据的正确性和任务的稳定性
对象存储的元数据加速
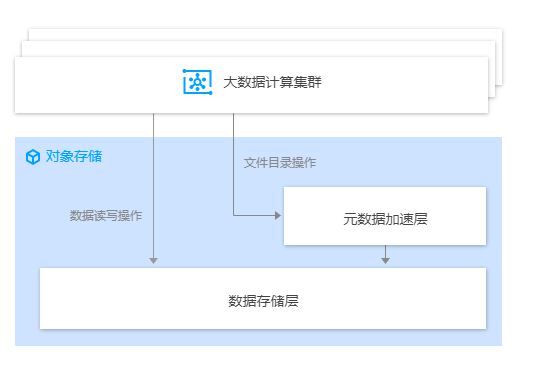
直观简述:元数据操作会路由到元数据加速层进行处理,小投入大收益
元信息数据(文件名,分块信息,分块所在的服务器等)存储在索引库表中。按主流公有云对象存储设计,会按照字典返回文件索引信息(索引信息存储在ssd盘上,拉取索引信息的性能会受限于SSD盘单进程限制),每个存储桶list qps很难达到很高的值
以腾讯云的测试结果举例
| 元数据数量 | 指令 | 开启元数据加速 | 未开启 |
|---|---|---|---|
| 5w | ls | 4.359s | 10.354s |
| 50w | ls -R | 7.065s | 21.376s |
| 1000个100KB文件的目录 | rename | 1.016s | 30.323s |
参考
- 1.Juicedata,从 Hadoop 到云原生, 大数据平台如何做存算分离 ↩
- 2.TencentCloud,听说你想把对象存储当 HDFS 用,我们这里有个方案 ↩
- 3.Meta, Taking Advantage of a Disaggregated Storage and Compute Architecture ↩
- 4.CSDN, Hadoop势微,云原生上位 ↩
- 5.阿里技术, 大数据上云存算分离演进思考与实践 ↩