大数据收集处理工具链简介
大数据收集处理工具链简介
DiffDay
HDFS存储格式探查
- 在 MapReduce 中,数据格式易于分割是被期望的特性
- XML,JSON 都不容易被分割,类似于它们的所有半结构化的格式特征好处是可以模拟复杂的数据结构
- 大规模的数据,存储空间和数据能支持模式演变(版本兼容)都是值得考量的因素
- 一些常见的序列化格式,如 PB,Thrift 等,都原生没考虑数据分割,一些第三方包的处理方式是在原基础上对格式进行扩展,加入分割块,但序列化/反序列化就需要专有配套的类库
- SequenceFiles/Avro,都是设计出来适配 MapReduce 的文件格式
Hive存储格式探查
-
分为元数据存储(通常在关系型数据库中)与数据存储两部分
-
数据存储构建在 Hadoop 的 HDFS 文件系统之上
-
基本的划分,有内部表外部表之分(数据是否全由 Hive 管理为判定依据)
- 常见其它平台有数据入库的过程,统一存储格式,数据清洗
- 通常业务直推的文件格式都是行格式组织,入库过程可转换为大数据场景友好的列存储格式
-
开放 SerDe 接口用以支持各种格式的文件解析
- 需要将解析类添加至 classpath 的查找路径,通过 addjar 的方式(支持本地或 hdfs 的 jar 包)
- 或者加入固定的 hive lib 目录或配置文件中声明(在公共平台上灵活获得配置支持较难)
Hive 的原生的存储格式选择
- TextFile:默认格式,行存储,默认列分隔符 0x01,压缩的text 无法分割和合并
- SequenceFile:压缩的文件可以分割和合并
- Avro(From Hive 0.10.1)直接读写 avro 格式文件
- RCFile (RecordColumnar File)
- 行列结合,同行数据不会跨 Block 存放,块内数据按列组织存储
- 对 schema 演化自持较差
- ORC(Optimized),从名字上就看出是 RCFile的升级
- 空间「压缩编码」& 性能优化
- 支持事务和 Update 操作(自 Hive0.14.0完整支持 ACID 操作)
- Parquet(From Hive 0.13 开始逐步支持),初始设计动机是存储嵌套式数据,如 PB,json,转成列式,方便压缩 和编码,减少 IO
ORC 和 Parquet都是 Apache列式存储引擎的顶级开源项目,由不同的厂家推广,性能优劣上 ORC 可能更佳(来自 netflix2014 的测试),Parquet 对嵌套式数据结构支持上更佳
| Parquet(parquet.apache.org) | Orc(orc.apache.org) | |
|---|---|---|
| 开发语言 | Java | Java |
| 主导公司 | Twitter/Cloudera | Hortonworks |
| ACID | 不支持 | 支持 |
| 修改操作 | 不支持 | 支持 |
| 支持索引(统计信息) | 粗粒度索引 block/group/chunk级别统计信息 |
粗粒度索引 file/stripe/row级别统计信息,不能精确到列建立索引 |
| 支持的查询引擎 | Apache Drill、Impala | Apache Hive |
| 查询性能 | 更高一点 | |
| 压缩比 | 更高一点 | |
| 列编码 | 支持多种编码,字典,RLE,Delta 等 | 支持主流编码,与 Parquet 类似 |
Hive 操作 JSON 文件
-
解析操作 JSON 格式的数据,需要引入对应 SerDe 类
- 在 Hive 安装目录 hcatalog 下有 hive-hcatalog-core-x.x.x.jar包可以采用
- 运行命令 add jar /appcom/hive/hcatalog/share/hcatelog/hive-hcatalog-core-x.x.x.jar
- 亦可添加 hdfs 上的 jar 包,如 add jar hdfs://AAA/BBB
-
因为不在 Hive 的默认配置中,所以每次运行都需要执行 add jar 命令
-
建表示例
1
2
3
4
5
6create external table spark_people_json (
`name` string,
`age` int
)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS TEXTFILE;
ORC和Parquet 的补充对比
引用[1]做的一个简单实验数据(建表,写数据,SQL 查),量化形象对比
| Format | 压缩算法 | 文件大小 | 耗时-秒 | 总CPU时间-秒(Cumulative CPU) |
|---|---|---|---|---|
| textfile | NONE | 98.2G | 41.521 | 3745.67 |
| ORC | ZLIB | 18.5G | 31.713 | 1107.44 |
| ORC | SNAPPY | 28G | 25.59 | 1234.89 |
| ORC | NONE | 87.6G | 40.571 | 1652.23 |
| Parquet | NONE | 88G | 33.318 | 5440.49 |
- 如果数据结构比较扁平,那么用 ORC,如果嵌套较多,用Parquet
- Parquet 脱始于 Google Dremel 项目,当初较吸引互联网大厂的眼球

日志落地文件仓库
- 日志数据基本均为可见打印字符
- 嵌套复杂数据结构较少
- 各业务格式风格不统一且存在变更扩展可能
- 业务端的数据应用需求不同(统计分析/导出)
推导出的方案建议
- 保留业务端的日志原始格式
- 数据的使用由业务方自行定制
- 无嵌套数据结构,哟给你固定分隔符的文本行,否则用 Json(hive 解析需要额外 jar 包的引入支持)
- 类似 PB,Avro,Thrift 及其它格式,亦可以,空间占用率下降的和模式演化能力增强,但可读性下降
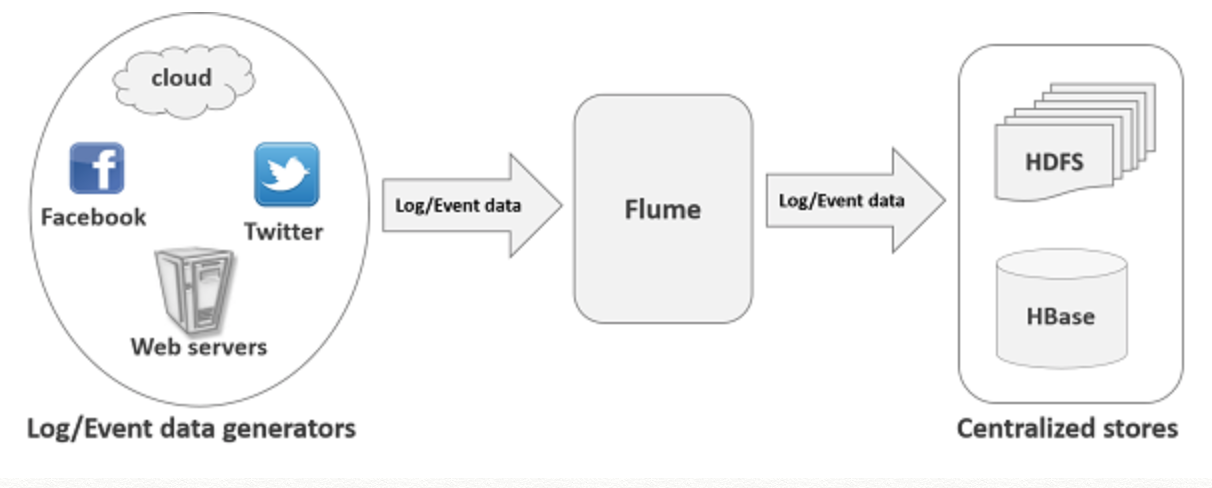
Flume
- Source --》 Channel --》 Sink 的三级概念设计及数据流向
- 每级概念均支持多类型实现
- 多种数据源,多种 channel,多种 sink 类型
- Source 中生产出 Event,对 Event 上可以进行自定义(拦截)处理,存入 Channel,Sink 保存数据至指定目的地
- Channel 的功能比较简单,性能瓶颈可能出现在 source 和 sink 两端,更容易出现在 sink 端。Sink 端可以通过成组多配置,来扩容提升处理能力(round robin 或其它负载均衡机制)
- Sink 类型支持多种
- Hive 要求表提前定义,存储格式为 ORC,分区分桶
结合 Flume 的日志落盘方案
- 开放字符型日志的上报接口(会自动附加换行)
- Byte[] 二进制型的接口,视需要后续开放,其放入不同的 kafka topic 中(sink 时不加换行符号)
- reportLog(String app,int version,String log)
- 落盘至 HDFS /应用目录路径/version/日期 对应目录下
- 指引业务建表时根据日期进行静态分区,每日脚本运行时,进行分区添加动作
数据推送及消费的流程
flowchart LR
A(日志上报至 Kafka 的
对应 topic) --> B(Flume根据 topic 的消息头
进行分流)
B --> C(sinks至
HDFS)
C -->D(建Hive表
『可选』)
D --> E(统计计算on
Hive/Spark)
E --> F(保存数据至 Hive 表
『可选』)
F --> G(回传数据至
业务数据库
『可选』)
数据供业务消费的方案机制
- 通过 Sqoop 脚本导出 Hive 表对应数据至业务库表
- 计算结果直接存入业务数据库表
- 计算结果存入 Hbase,业务访问 Hbase
- 统计结果推送邮件作为内容查看
Spark的 API
- RDD
- DataFrame/DataSet
- DataFrame是 SparkSql 在处理数据时的核心数据结构
- 类似于数据库的表的形式进行存储,按行组织
- 选择编写 SQL 和编写 Spark 程序(Scala/Java/Python)的依据
- 类同于用存储过程和普通 SQL 的差别
| RDD | 非结构化的数据处理,可对数据进行最基本的转换,处理,控制 | |
| DataFrame/DataSet | 提供类似数据表的抽象,处理数据上对数据分析人员更有熟悉感 | DataSet 可看作是编译时类型检查版本的 DataFrame |
引用参考
- 1.github orc与 parquet 对比 ↩



喜欢这篇文章的人也看了

评论
匿名评论隐私政策