从Error Based Injection看MySQL group by过程
从Error Based Injection看MySQL group by过程
DiffDay
Error Based Injection
作为SQL注入的一种
- 构造恶意的输入来引发报错
- 数据回显受限时,通过构造特定的报错来获取数据库中的特定数据
利用回显的报错注入
不断尝试,进行猜测目标数据库的基本信息和sql语句构造的形式
利用报错信息的报错注入
最典型的是双注入查询
在一个查询中再套一个子查询,精心构造报错,这些报错将泄露数据库数据[1]
- BIGINT等数据类型溢出
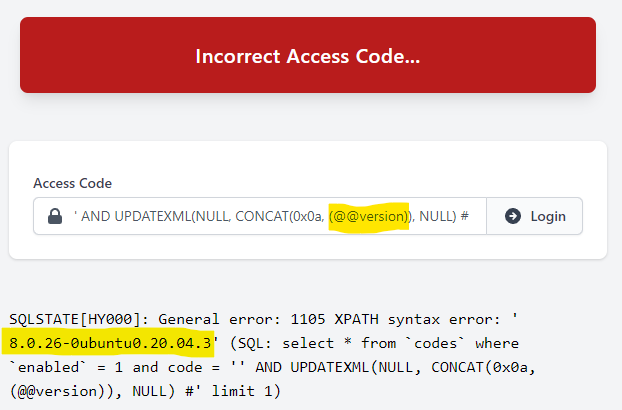
- Xpath语法错误,如extractValue(目标文档,xml路径),第二个参数当你写入其它格式就会报错,如第二个参数改为concat(‘!’,select database()),!开头不是xml语法,就报错异常回显。类似的函数还有updateXml
- concat+rand+group by导致主键重复
- 类型转换报错
- And More
看看这套group by组合
1 | select count(*),CONCAT(version(),floor(rand(0)*2)) as x from information_schema.tables group by x; |
触发报错
1 | [Err] 1062 - Duplicate entry '5.7.30-log1' for key '<group_key>' |
这个错入注入里 rand() 指定参数很重要,一旦制定后,生成的随机数队列就是确定的,结合 *2 并 floor后,其生成的值只有0和1两种情况
这个报错不得不说是MySQL的bug,因为在MS SQL和Access里并不会出现,联想到先前一位程序员大法师吐槽 最流行的数据库MySQL代码乱糟糟
其根源在于rand函数在select后的第二阶段,又被再次运行所致
- select 发现group key不存在,设定下一阶段动作转态为insert操作
- 在insert时,再次运行rand(),进行插入动作,再运行到第3行就出错了。前两行的统计结果也是错的。
- floor(rand(0)*2)生成的序列为0,1,1,0,1,前面的count结果也是错误,本应两行count各为1,计算结果却是5.7.30-log1计数为2
- 前两行将0,1,1给用掉了,第3行的0,1撞在枪口上
Drill-Down看看
随机数
计算机因为是程序控制,只能产生有规律的随机数,即成为伪随机数,咱们看个例子
1 | Rand_seed = ( rand_seed * 123 + 59 ) % 65536; |
你当黑盒看,放进一个数,会出来一个特定的数,并把这个数当下一次的种子再放进去
- 如果你每次放进去一样的种子,生成的随机数列就是一样的了。这样的随机数设计有无好处?有,可重入
- 有些软件,放时间种子是内置的默认操作,有些则将种子设置开放给调用方
- PG数据库的random函数就不接受参数,JS的Math.random()也不接受参数
配套什么操作才出错
-
max,avg,min,sum均一样,都在第3行出错
-
没有count类函数是否出错?不出错。
剖析过程
group by执行过程中的insert逻辑不同,等同于select distinct的语义(性能相同,distinct当有limit加持时,性能更好)
- 创建临时表,且创建唯一索引
- 遍历源表,依次取数据插入临时表。碰见唯一键冲突则跳过,否则插入成功(此处没复用出bug的代码)
- 遍历完成后,将临时表作为结果集返回给客户端
Drill-Down再看group by
一个标准的group by局域包含排序,分组,聚合函数。当group by语句中没有order by,默认按group字段升序排序。
| filtered | Extra |
|---|---|
| 100 | Using temporary; Using filsort |
explain看常见分析结果:Using Index能用上索引,Using temporary使用临时表,Using filsort需要排序
- group by字段用不上索引,那么临时表常见就要搬出来救场,故也为什么索引对性能很重要
- filsort并不是说通过磁盘文件进行排序,只是告诉我们排序操作,或可理解为不按表中索引的排序
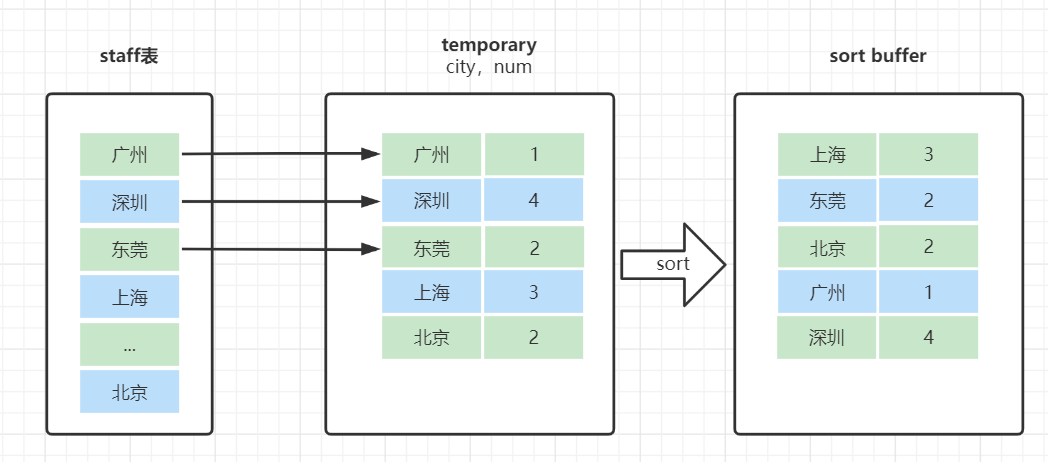
内存临时表若达到tmp_table_size的大小(默认16M),就会将内存临时表升级为磁盘临时表,然后重新开始遍历计算(丢弃重做纯浪费)
执行过程一边读数据,一边直接得到结果,是不需要额外内存的,要额外内存保存中间结果(如遍历无序数据)或过程要利用唯一索引约束等,就要搬出临时表救场
遍历完成后,再根据group by字段做排序,得到结果集返回给客户端
觉得文字不够形象的,可参考此文章[2]的配图加深认识
Drill-Down第三弹:order by
排序执行过程:
sort_buffer是有序数组,临时表是二维表结构
若sort_buffer设置的大小不够大,会用临时表来辅助排序(增大sort_buffer_size可尽量减少对排序数据进行分段,buffer区放不下,分治;分段会造成MySQL不得不使用临时表进行交换排序)
-
如何确定是否使用了临时文件来完成排序呢?[4]
1
2
3
4set session optimizer_trace="enabled=on"; -- 开启optimizer_trace
运行SQL语句;
select * from information_schema.OPTIMIZER_TRACE'; --查询优化跟踪过程
set session optimizer_trace="enabled=off"; -- 关闭optimizer_trace结果中的number_of_tmp_files表示排序过程中用到的临时文件数,因为sort_buffer放不下
-
filsort也是在内存中排序的,排序区sort_buffer是每个thread独享的
- 双路排序【rowid排序】:取排序字段和行数据指针,放进sort_buffer中完成排序,是MySQL认为磁盘外部排序还比不上回表查询的效率时的选择,好处是节省内存
- 单路排序【全字段排序】:所有字段在sort_buffer中进行排序,好处是不用再查表记录(减少随机IO),排序结果直接返回,性能更好(此改进算法子MySQL4.1出现,应对大内存时代)
- 当max_length_for_sort_data更大,就用单路排序算法。否则才降级为双路排序,排序效率高,就要加大此参数值,结合去掉不必要的返回字段
觉得文字不够形象的,可参考此文章[3]的配图加深认识
Drill-Down第四弹:概括总结与优化
- 分组(group by)列无索引的数据,因为无序,所以要创建临时表,然后一个个判断属于哪个分组,再根据分组进行排序
- group by的优化
- 索引不必赘述,顺序访问获取要返回的字段或计算聚合函数,再友好不过。列值变化当前组就访问结束,将之前的数据直接返回,避免创建临时表,也不用sort_buffer额外排序,大大提高效率
- MySQL 5.7支持generated column机制,来实现列数据关联更新,在此列上加上索引,可更加便利达到目标效果
- 不用排序的可禁止排序,添加order by null,这样你在explain就可以看到效果,没有了filesort
- (若分组字段使用率很低,欠缺索引)很大的表,内存临时表放不下转成磁盘临时表,也是耗时的,有无更深的优化方法?
- 可试用 SQL_BIG_RESULT这个hint来暗示优化器改变执行过程【告诉优化器直接使用磁盘临时表,省却内存放不下,丢弃,再用磁盘临时表的浪费动作,且用排序算法】
- 大喇叭宣告:这个语句涉及的数据量很大,请直接用磁盘临时表
- 如未达到磁盘临时表的使用条件,仍不会使用磁盘临时表
- 优化器一看,磁盘临时表是B+树存储,存储效率不如数组来得高,语句最终的结果使用场景为全块扫描,没有范围查找。优化器会使用数组结构的磁盘临时表(类比memory引擎内存临时表来理解,和磁盘临时表默认InnoDB不同,数据单独存放,索引保存数据位置。采用无序hash索引,数据按照写入数据顺序存放,本质与数组无差)
- SQL_BIG_RESULT+order by null explain结果只展示filesort,Using temporary没出现
- 索引不必赘述,顺序访问获取要返回的字段或计算聚合函数,再友好不过。列值变化当前组就访问结束,将之前的数据直接返回,避免创建临时表,也不用sort_buffer额外排序,大大提高效率
此段也可以对照[2]来加深形象理解
参考
- 1.HatBoy MySQL报错注入 ↩
- 2.腾讯云 看一遍就理解groupby ↩
- 3.CSDN MySQL排序内部原理揭秘 ↩
- 4.CSDN MySQL优化器原理 ↩