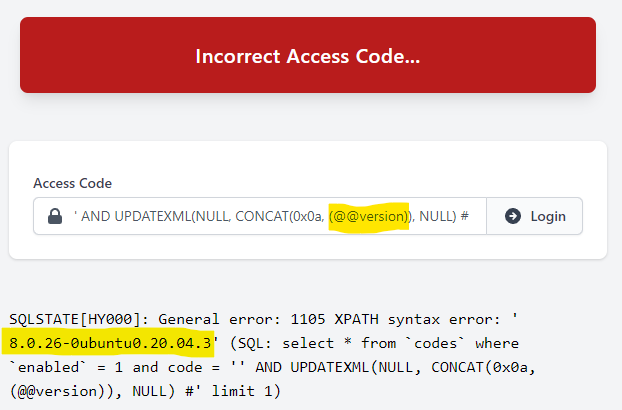
数据库schema概念差异
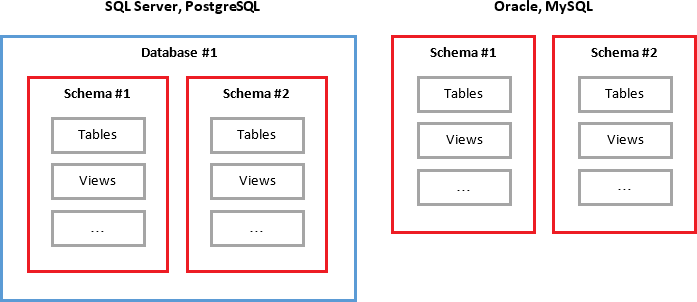
数据库schema概念差异
DiffDay
涉及到数据库的模式有很多疑惑,问题经常出现在模式和数据库之间是否有区别,的确有区别,取决于数据库供应商,各家数据库系统倾向于以自己的方式处理模式(schema)这个概念。
概念厂商差异
MySQL
MySQL文档指出:在概念上,模式是一组相互关联的数据库对象,如表,表列,列的数据类型,索引,外键等等;但在物理上,模式和数据库是同义的,所以schema和database是一回事,在MySQL中create schema和create database可以混用
Oracle
A schema is a collection of logical structures of data, or schema objects. A schema is owned by a database user and has the same name as that user.Each user owns a single schema
Oracle的文档却指出,某些对象可存储在数据库中,但不能存储在schema中,因此二者不是一回事,schema是数据或模式对象的逻辑结构的集合,由数据库用户拥有,且与该用户具有相同的名称,也就是每个用户拥有一个独立的schema。Oracle的schema与数据库用户密切相关。
在oracle中,create schema实际并不创建一个模式,因为在创建用户时,数据库用户就已经创建了一个模式,也就是说在oracle中create user就创建了一个schema。create schema语句允许你将schema同表和视图关联起来,并在这些对象上授权,从而不必在多个事务中发出多个SQL语句
SQL Server
The names of tables,fields,data types and primary and foreign keys of a database
SQL Server说schema是server内部一个独立的实体,和database不是一回事,包含了数据库的表,字段,数据类型以及主键和外键的名称。与MySQL不同,create schema创建了一个单独定义到数据库的模式,但自然也和oracle不同,在SQL Server中,一旦创建了模式,就可以往模式中添加用户和对象。
差别清单
| DBMS | Database/Schema | Implicit schema |
|---|---|---|
| Just schemas | ||
| Oracle | Server => Schema = User | N/A |
| MySQL | Server => Database = Schema | N/A |
| MariaDB | Server => Database = Schema | N/A |
| Teradata | Server => Database = Schema | N/A |
| Firebird | Server => Database = Schema | N/A |
| Interbase | Server => Database = Schema | N/A |
| SQLite | File = Database = Schema | main |
| Databases and schemas | ||
| SQL Server | Database => Schema | dbo |
| PostgreSQL | Database => Schema | public |
| Azure SQL Database | Database => Schema | dbo |
| IBM Db2 | Database => Schema | N/A |
| Amazon Redshift | Database => Schema | public |
| Snowflake | Warehouse => Database => Schema | public |
| SAP/Sybase ASE | Database => Schema | dbo |
| SAP HANA | Database => Schema | N/A |
| Vertica | Database => Schema | public |
| IBM Informix | Database => Schema | N/A |
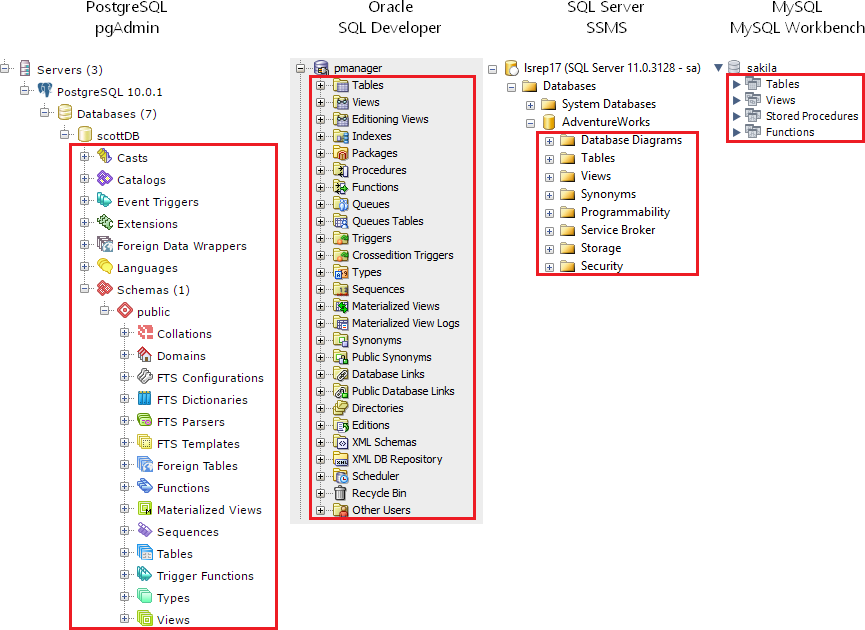
逻辑概念的命名空间
schema的另一个含义是大多数关系型数据库引擎用于对对象分组的特定元素。
可以把schema认为是一个命名空间(namespace)或容器(container),其中包含有表、视图和函数等。
数据库(database)的所有者就是schema的所有者
schema的功效
主要在以下的场景中将database拆分为多个schema(namespace):
- 容易为整个schema来分配权限,可以基于用户访问权限应用安全权限来分隔和保护数据库对象
- 为两个或多个不同的表(或其他对象)使用同一个name
- 对相似的对象进行分组来降低复杂度,数据库对象的逻辑分组可以被数据库管理起来,schema可以将数据库对象组织成逻辑分组。
- 同一个schema可以用在不同的数据库中
- 可以很容易地对几个schema的ownership进行切换
国内的信创数据库生态
产业图谱
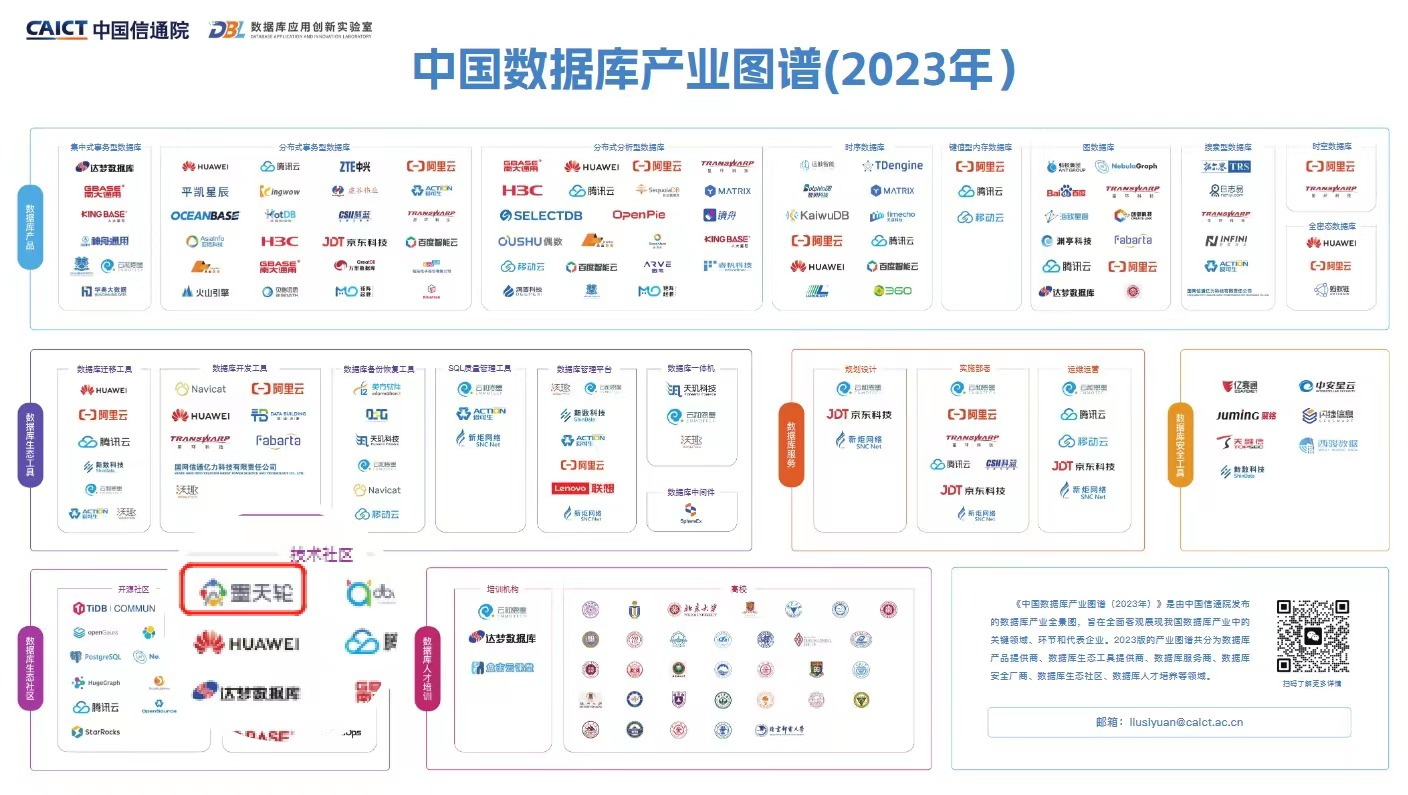
征集+评选,填写“数据库产品与产业图谱调研表”,发送至liusiyuan@caict.ac.cn,邮件主题为“企业名称+数据库产品与产业图谱”。权当个信息黄页看吧,中国组织编纂的官方机构不少呢,且并不是NGO,你去参加IT技术峰会也能感知到。
数据库溯源图谱
经实证mermaid的mindmap效果离专业的脑图工具还有不小的差距
mindmap
root[国产OLTP数据库谱系]
((自研))
(Oracle兼容)
达梦DMB
浪潮K~DB
科蓝软件SunDB
(RocksDB分布式)
TiDB
OceanBase
(巨杉数据库SequoiaDB)
((PostgreSQL))
(华为 Open Gauss)
海量 VastBase
人大金仓 KingBase
南大通用 Gbase 8c
神舟通用 神通V7
中国移动 磐维数据库
云和恩墨 MogDB
超图软件 Yukon禹贡
超聚安 FusionDB
(PGXC)
华为 GaussDB
腾讯 TBASE
亚信 AntDB
(PG社区版)
瀚高 ivorySQL
优炫 UXDB
阿里 PolarDB~PG
恒生电子 LightDB
浪潮 kaiwuDB
中国电信 TeleDB PG
((MySQL))
阿里
RDS~MySQL
PolarDB~mysql
腾讯 TDSQL
万里开源 GreatSQL
中兴通讯 GoldenDB
热璞 HotDB
星环 KunDB
百度 GaiaDB
中国电信 TeleDB~mysql
石原子科技 StoneDB
((Informix))
南大通用 Gbase 8s
星瑞格 SinoDB
华胜 xigemaDB
开源社区精神在于众人拾柴火焰高,不过在数据库主版本一路迭代时,大多数企业并未安排数据库升级合并,另一些基于自身需求做的功能增强和社区主版越行越远(未积极融入社区讨论与回馈),最终变成主版本更新迭代很多代了,自己的核心还停留在上个世纪,这点上在PG社区尤为明显(国内基于PG的自研数据库,已经没办法再去merge最新的PG15的代码,如PolarDB for PG,和PG的差距越来越大,最终决定开源自己的Polar for PG版本)。
用户使用数据库,必伴随着应用系统,中间件,操作系统,硬件平台等上下游产品,另一方面在整个数据库销售链条当中也涉及分销商,增值渠道商,独立软件开发商,系统集成商,数据库运维伙伴一系列的商业链条。从学术上来看,又要考虑高效合作(顶会期刊与成果转化),独立应用开发商合作,周边生态产品合作(管理工具,调优工具,报表工具,SQL工具)。
用户选择视角
对用户来讲,考察主要在如下几点:
- 兼容性:是否兼容主流标准,主流开发工具和报表工具
- 合作伙伴:是否有足够多的合作伙伴,已基于该产品进行了二次开发或加工,有多少解决方案
- 案例多不多:踩着别人的脚印走,不容易踩到💩
谱系说明
Oracle兼容
主选手是武汉达梦,及浪潮K-DB数据库,产品功能和特性,基本复刻Oracle,如RAC这样的技术。
MySQL兼容
最为流行的数据库,簇拥衍生品肯定不缺。但一方面MySQL存在数据量上面的瓶颈,和Oracle的差异化概念设计也一定程度上制约它的迁移替代机会,给了PG库施展魅力的空间。
PG兼容
开源界除开Mysql,就是PostgreSQL备受喜爱,除开上面说的MySQL问题,另MySQL/MariaDB的GPL开源协议,不允许衍生品作为闭源软件发布和销售,只能卖服务,这使得国内厂商望而生畏,导致大量倒向BSD协议的PG,如巨杉数据库,腾讯TBase等。
Open Gauss体系
源自PG9的变体,现在也作为一个独立的生态体系存在。自主可控了,国内有不少数据库转投open gauss阵营,如人大金仓,MogDB等。
Informix兼容
2005年,IBM对中国公司销售informix源代码,与IBM签订源代码授权的公司有华胜天成,南大通用和星瑞格,故成为引进Informix源代码发展国产数据库的代表
自研分布式
基于LSM树的数据库,因其优秀的写友好及高并发,也有非常优秀的产品。典型的就是TiDB和OceanBase,基于LSM-Tree,结合Paxos或Raft协议实现分布式高可用。
另SequoiaDB巨杉数据库,是一款金融级分布式数据库,支持创建多种类型数据库实例MySQL,MariaDB,PostgreSQL,SparkSQL四种关系型数据库实例,JSON文档类数据实例,及S3对象存储的非结构化数据实例。