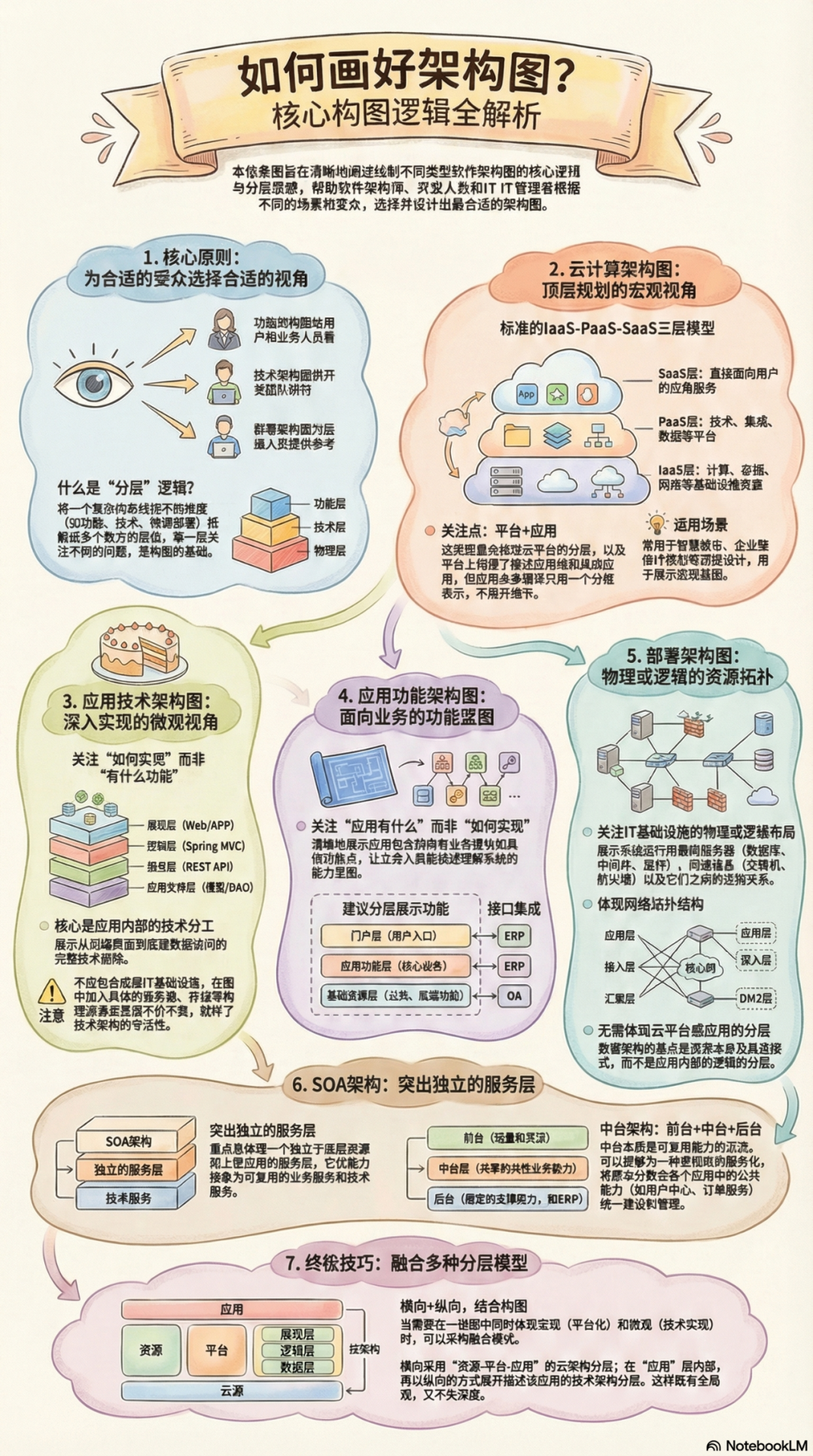
通用机器人指标
通用机器人指标
DiffDay通用机器人指标
共识指标
-
准确率
-
召回率
-
两个指标做二维图,就可综合做出P-R曲线图,横轴为召回率,用以衡量模型的性能
-
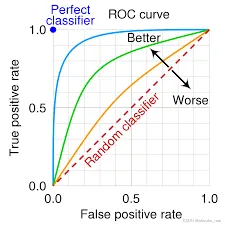
ROC(受试者工作特性曲线),横轴为假阳性率,纵轴真阳性率。通过不断调整区分正负的阈值,可得到一个曲线。从医学上看,横轴就是误诊率,纵轴就是检出率

二战期间,雷达兵任务之一就是死死盯住显示器,观察是否有敌机来袭。每个雷达兵都可能研究飞鸟信号和飞机信号的区别,以便增加预测准确性。
问题在于:每个雷达兵(模型)都有自己的判断标准,谨慎的易误报,胆大的易漏报。为了研究每个雷达兵预报的准确性,汇总雷达兵的预报特点,作图在一个曲线上,就是ROC曲线。
- ROC曲线能降低不同测试集带来的干扰,更客观衡量模型本身的性能。在很多实际问题中,正负样本数量波动,相差悬殊,如广告有转化的数量相较于无转化少很多,不同的测试集,P-R曲线变化大,ROC曲线相对稳定,广泛用于排序,广告等领域。医学上也是(越陡峭,表明真正的正样本排在前面)
-
若你更希望看到模型在特定数据集上的表现,PR曲线能更更直观反映其性能。
ROC两个指标,一个聚焦于正例(TP),一个聚焦于负例(FP),所以比较均衡。PR的两个指标都聚焦于正例,所以对正例量更为敏感。
-

用户维度的指标
- DAU
- 意图丰富度(使用率 > x%的意图个数)
- 满意度评估(语音语义的情绪分类)
对话型
公共指标
- 达成率
- 交互效率(步长)
细分指标
问答型
- 求助人工比例
- 重复同样问题比例
- 没答案类的比例
任务型
- 留存率
闲聊型
- CPS(对话轮数)
- 相关性 & 新颖性
搜索特性指标
很多指标靠常规的用户行为上报设想,是难以覆盖的。全面的收集必须【谋划在先、才能为目标节省时间】。如Search exit,高跳出率意味着搜索引擎给出的结果,用户找不到他想要的,但此类行为收集一般不在早期规划中。
- Request/Session
- CTR(Click-Through-Rate): 搜索结果点击次数占访问次数的比例
- 平均点击深度
- Search exit:跳失率
| 评估指标 | 召回(Recall) | 排序(Ranking) | 综合 |
|---|---|---|---|
| 查询无结果率 | $\frac{无结果搜索PV}{总搜索PV}$ | ||
| 平均点击深度 | $\frac{PV中用户【首次】点击链接所处的深度}{搜索次数}$ | ||
| CTR | $搜索结果点击次数/访问次数$ | ||
| 跳失率 | 进入页面后没有任何操作, 直接退出的比例 (没有点击搜索结果,没有翻页等) |



喜欢这篇文章的人也看了





评论
匿名评论隐私政策