存算分离
存算分离
DiffDay
概念内涵和缘由
计算是核心,数据是原料或产物,计算能脱离存储?
概念窄化明确
-
存储:持久化
-
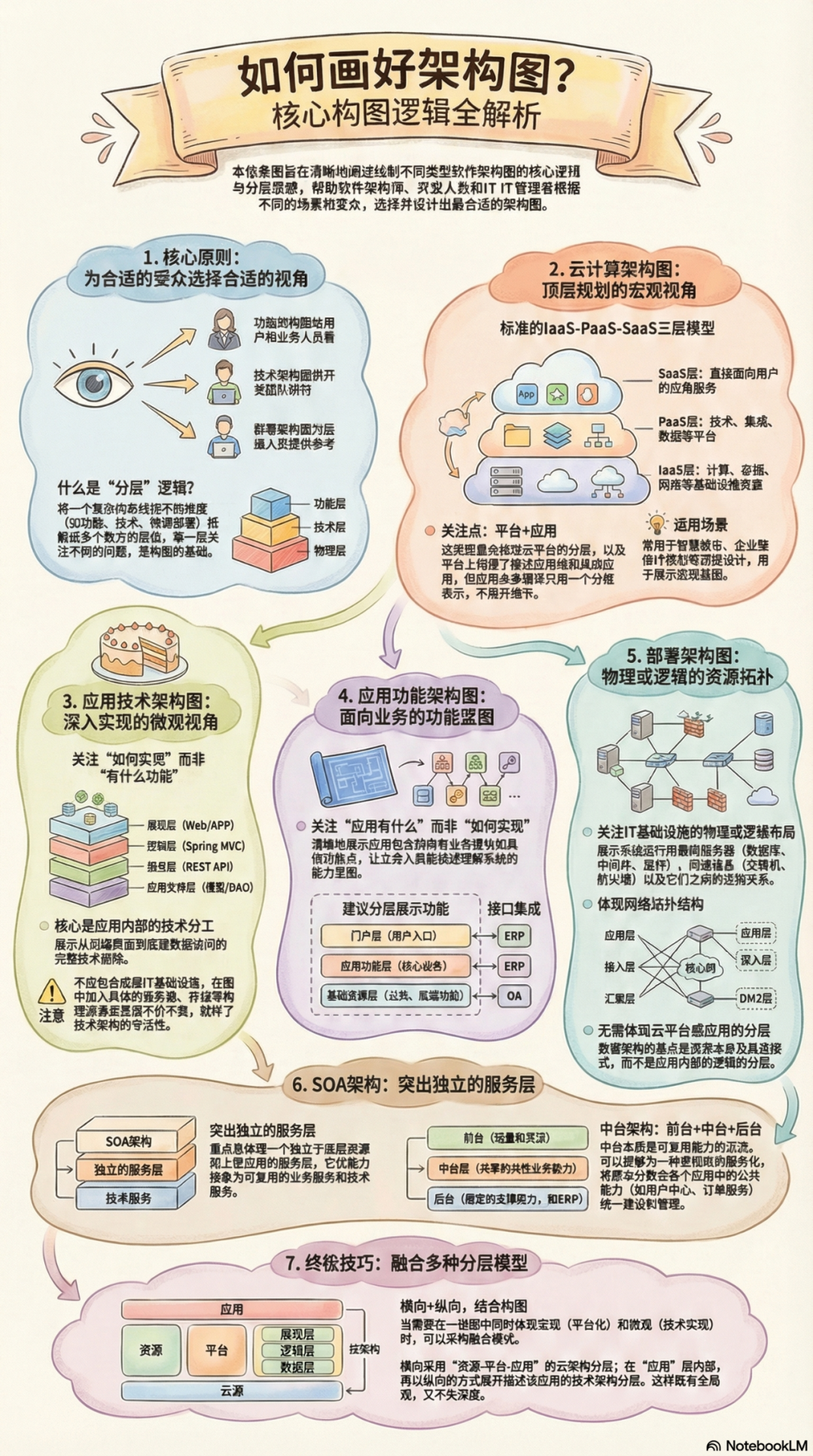
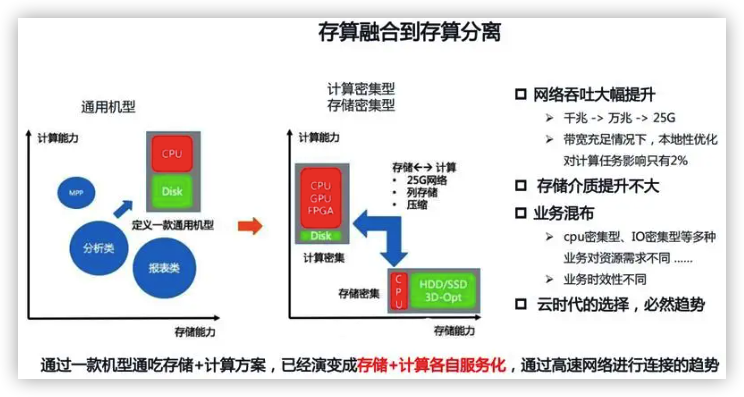
计算过程中的存储归纳为计算(cpu+内存)
新瓶装旧酒?
20 年前就有NAS-网络附加存储(使用 TCP/IP协议的以太网文件服务器),价格较贵扩展困难。重提计算和存储分离肯定要做出点不一样,我们放到后续展开
综合言之,经典计算机概念中,都是移动存储到计算。但在大数据体系下,大家慢慢接受移动计算到存储(MR),哪怕 MR 本质都还是存储和计算耦合的架构.
存算分离的弱势
在讲分离之前,还是要明确完全的存储与计算分离是伪需求(网络传输与我们当前 CPU 的处理速度还是完全不匹配)
随着技术的进步,瓶颈不是在网络速度,在磁盘 IO 速度,计算和存储耦合的架构缺点逐渐暴露。
机器浪费
计算先到瓶颈,还是存储先到瓶颈,两种情况往往不一样,时间点也不一样
- 计算不够,加一台机器
- 存储不够,也加一台机器
这样粗放的操作架构中的浪费明显
机器配比需频繁更新
一个公司的机器配型(CPU、内存、存储)一般比较固定,业务的不断发展,配型需要不断更新扩充变化
扩展不易
存储不够了经常需扩展,耦合模型下扩展就存在迁移大量数据
RDMA
既然基于网络分离,又不同于 NAS,怎么装新酒?酒又是什么味道?
前面说 IO 才是瓶颈,现有的网络机制又瓶颈? – YES
SSD 催生网络接口性能要升级
- 10Gbps 带宽下,ISCSI 架构,iodepth=32,block-size=4k,随机读写,IOPS在 TCP 下能做到 160k,吞吐能力超过网卡上限的一半,远超单磁盘能力,所以已很够用。
- SSD 性能,单盘 180k 以上的 IOPS,NVME SSD 单盘 550k iops,SSD 时代存储网络中,呼声要变革现有网络传输机制
RDMA 的特征描述与历史沿革
目标:降低网络吞吐时延
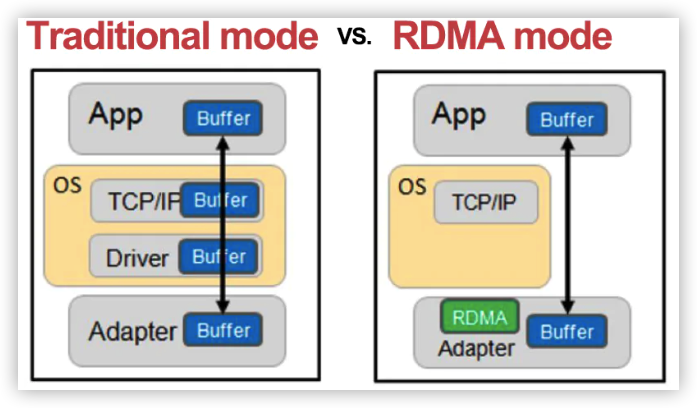
核心关键词:Direct
详细解释
- Remote:通过网络传输
- Direct:没有内核参与,有关发送传输的所有内容都 offloading 到网卡上
- Memory:在用户空间虚拟内存与 RINC 网卡直接进行数据传输,不设计系统内核,没有额外的数据移动复制
- Access:Send、Receive、Read、Write、Atomic 操作
在 RDMA 技术下,吞吐能力比 TCP 高 6-7 倍,应用于 GPU 间,能带来一倍的时延下降,小包传输方面能带来 3 倍性能提升,能达到 2G 的通信带宽时延从 20 微秒下降到 10 微秒
罗马不是一日建成的
- CPU 参与 TCP 协议栈的处理,封解包涉及用户态/系统态数据传递
- TCP Offloading Engine:主机处理器的工作转移到网卡上(万兆网卡一般都支持)
- User-Net Networking
- 协议处理部分移动到用户空间去处理
- U-Net 应用程序可通过 MUX 直接访问网络
- U-Net 的 virtual NI 为每个进程提供了一种拥有网络接口的错觉
- 避免用户空间数据移动和复制到内核空间的开销
- VIA(Virtual Interface Architecture)
- 标准化 user-level 的网络通信模式
- 组合 U-Net 接口和远程 DMA 设备
实施特点
- 把资料直接传入计算机存储区,将数据从一个系统快速移动到远程系统存储器中
- 消除了外部存储器复制和上下文切换的开销
- 解放内存带宽和 CPU 周期用于改进应用系统性能
通过专有的 RDMA 网卡,提供一个专有的 verbs interface 而不是传统的 TCP/IP Socket Interface,当数据路径建立后,应用程序可直接访问用户空间的 Buffer
网络实现
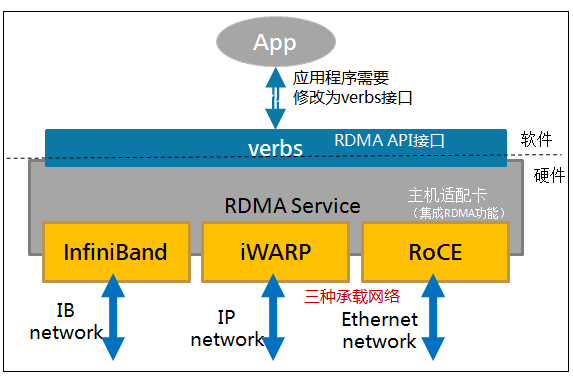
Infiniband(IB)
- 专为 RDMA 设计的网络,从硬件级别保证可靠传输,无损链路层,可防止使用链路层(基于拥塞)流量控制的损失
- 需要支持该技术的网卡和交换机:硬件成本+运维成本
- 性能最好,可达到 40Gbps
- 最早 IBM 和 HP 一群大佬在搞,有 10 几年历史,现在是 IBM 控股的以色列公司 Mellanax 在做
基于以太网的 RDMA 技术
- 支持 verbs 接口
- 仅需使用特殊网卡,都还使用 IB 定义的 user space api
RoCE(互联网圈火)
Mellanax 鉴于 IB 过于昂贵这个事实推出的一种低成本产品,较低网络标头是以太网标头,较高网络标头(包括数据是Infiniband标头)
- RoCEv1: 基于以太网链路层实现的 RDMA 协议(交换机需支持 PFC 等流控技术,物理层保证可靠传输)
- RoCEv2: 以太网中 UDP 层实现
iWARP
- 在 TCP 上执行 RDMA 网络协议
- 网卡特殊–支持iWARP(使用 cpu offloading),否则就丧失大部分 RDMA 优势了
- 实际上用得不多
为啥没成为标配
技术难度
- 去掉操作系统这个中间层,很多事情变得复杂化了
- 新接口 ibverbs/rdmacm,暴露了很多细节,如内存注册,要考虑 RDMA 网卡缓存容量不够
- 多数应用其实都不会真正去调 Socket
- 欠缺通用成熟的 RDMA 扩展,不友好于上层应用开发者
硬件成本
- 需更新网卡和中间交换设备
- 近几年才上万兆网卡,还不舍得换更贵的
场景
不考虑通用,真正有动力采用 RDMA 的,使用已经很广泛
- 分布式 AI 框架
- 分离式存储架构
- 非必要情况下,都在考虑收益,如 Spark 这样的任务,真正有网络 IO 的 shuffle 阶段可能只占整个任务的 3%~5%,更多是离线,觉得未到非用不可的地步

DB 篇
NewSQL 的新趋势
数据库集群的传统矛盾
- 分布式事务
- 集群吞吐量线性扩展
NoSQL 和 SQL 的融合
- NoSQL 大规模,高吞吐,易扩缩容,自动容错
- SQL 的通用性,支持复杂查询,分布式事务
架构带盐人
Google Spanner(扳手)
- Share Nothing
- 重点解决分布式事务和性能线性扩展的矛盾
Amazon Aurora(极光/曙光)
- Share Storage
- 存储分布式化,突破物理单机的限制
- 一写多读,更高的吞吐量
Aurora 模式优势说明
优势场景
- 读多写少-性能提升
- 成本是商用解法的1/10
- 应云而生:节约成本,敏捷创新 – 企业上云的核心驱动力
分离优势总结
- 提升资源利用率,降低云成本。共享存储,空间扩展更简单
- 相比一主两从的传统 RDS 集群具备更高的性能,写性能扩展
- 更有利于数据库实例实现一写多读
- 存储计算分离,且把存储计算的网络流量降到最低
国产类 Aurora 数据库 Cynos(北极星)
-
计算层:负责SQL解析、日志生成等;
-
存储层:负责数据存储,日志归档,日志合并等。
日志即存储,主从内存页同步
- 主客户端不断将 CynosStoreJournal(CSJ)从主实例发送到从实例
- 与relaylog不同,不用等到日志全部 Apply
- DB engine 就可以读到这些日志所修改的最新版本
日志转换为页由存储层消化,只要主实例将日志持久化至Store Node,从实例即可读到这些日志所修改的最新版本数据页,特别适合一写多读的场景
CSJ 比 Binlog 更底层,不讲细节,只描述能力,类型有如下几种:
- SetByte
- SetBit
- ClearBlock
- DataMove
- userDefined
CSJ 的抽象尝试隔离数据库引擎,不仅局限于 postgresql,设定基于块/页的,都可以转换成这 5 种日志来,这种非典型的做法带来了理解的复杂性,也可以对照 Aurora 的文章来理解。
用户态 IO
- 提升磁盘操作效率:SPDK(Storage Performance Development Kit)provides a set of tools and libraries for writing high performance ,scalable ,user-mode storage applications
- 解决网络传输效率
- RDMA(硬):RDMA 与 TCP 对比测试中,可明显看到 4K 数据的传输平均时延缩短 6~7us(微秒),在 4K 数据的 echo 测试中,CPU 使用率降低了 65%
- 日志即存储(软)
- 计算层不再将脏页发送到数据层
- 只发增量日志,存储层异步将日志转换为数据页
- 写流量在某些基准测试下,能减少 60%
分层设计(以兼容 pgsql 举例)
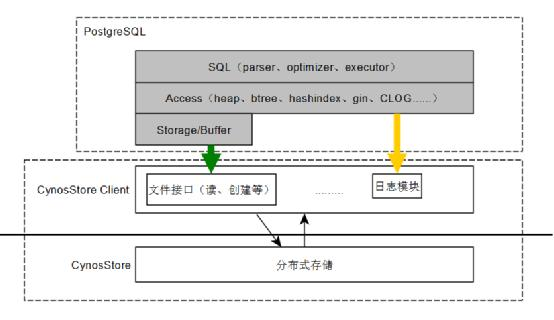
灰色部分是 PostgreSQL 内核原生模块
-
SQL 引擎
- 词法/语法分析
- 语义分析
- 查询重写/优化
- 查询优化
-
Access:数据库访问层,定义了对象的组织方式和访问方法
-
Storage/Buffer
- buffer pool和存储管理
- 用文件接口对数据文件进行读写
- CynosDB 使用 CynosStorageClient 对 CynosStore 中的文件进行操作
参考
- 1.CSDN RDMA的三种实现方式 ↩
- 2.博客园 详解RDMA 架构和技术原理 ↩
- 3.腾讯云 CynosDB的计算层设计优化揭秘 ↩